Decision trees are popular because they are easy to inspect. A prediction can be explained as a path of simple rules: if this feature is below a threshold, go left; otherwise, go right.
But that simplicity also limits them.
A standard decision tree usually splits on one feature at a time. These are axis-aligned splits. They are easy to read, but they can require many nodes when the true decision boundary is curved, diagonal, multiplicative, or otherwise not aligned with a single feature axis.
The paper “Symbolic Regression Enhanced Decision Trees for Classification Tasks” by Fong and Motani proposes a direct way to improve this: use symbolic regression to discover richer split rules inside the decision tree.
The result is a Symbolic Regression Enhanced Decision Tree, or SREDT.
Why Standard Decision Trees Struggle
A normal decision tree split looks like this:
x_i < k
That means the model chooses one feature and one threshold. This is interpretable, but limited.
Suppose the true boundary depends on an interaction such as:
x_0 * x_1 < 0
A standard tree cannot express that interaction in one split. It must approximate the boundary through many axis-aligned cuts. The tree becomes deeper, larger, and less explainable.
Oblique decision trees improve this by using linear combinations of features:
h_0 + h_1*x_1 + h_2*x_2 + ... + h_d*x_d < 0
This allows diagonal hyperplanes. But oblique splits can become dense because they may involve many input features. A split using every feature is harder to explain and can be more sensitive to perturbations.
SREDT sits between these ideas. It keeps the tree structure, but lets each split be a symbolic expression.
The Main Idea
Instead of asking:
Which single feature and threshold should split this node?
SREDT asks:
Which symbolic expression and threshold best split this node?
For example, symbolic regression might discover:
x_0 * x_1 < 0.05
or:
sin(x_0) + x_1^2 < 1.2
or:
x_2 / (x_3 + 1) < 0.7
The symbolic expression becomes the decision rule at that node. If the expression is compact, the split can still be readable. If it captures the true structure of the data, the tree can become much smaller.
That is the central advantage of SREDT: it expands the search space of possible splits while trying to preserve interpretability.
Symbolic Regression as a Split Generator
Symbolic regression searches for mathematical expressions that fit a task. Unlike ordinary regression, where the model form is fixed, symbolic regression searches over both the structure of the expression and its parameters.
In SREDT, symbolic regression is used to generate candidate split functions.

The symbolic regressor works roughly like a genetic programming process:
- Create a population of candidate symbolic expressions.
- Evaluate each expression as a possible split.
- Select the better expressions.
- Apply mutation and crossover to create new candidates.
- Repeat for several generations.
- Return the expression that produces the best split.
The split quality can be scored using a standard decision-tree criterion such as Gini impurity.
For each expression, SREDT also finds a threshold. The expression maps every data point to a numeric value, and the threshold divides those values into left and right branches.
So the final split has the form:
f(x) < threshold
where f(x) is discovered by symbolic regression.
From CART to SREDT
SREDT keeps the recursive tree-building structure of CART, but changes how a split is selected.

In a standard decision tree, the algorithm loops over features and thresholds. It chooses the split that best improves a criterion such as Gini impurity.
SREDT replaces that feature-threshold search with symbolic regression.

At each node:
- A symbolic regressor proposes candidate expressions.
- Each expression is evaluated over the node’s data.
- The best threshold for that expression is selected.
- The split is scored with a criterion such as Gini impurity.
- The best expression-threshold pair becomes the node’s rule.
- The process recurses on the left and right child nodes.
This means SREDT remains a decision tree. It still produces a hierarchy of rules. But each rule can be more expressive than a single feature threshold.
Why This Can Improve Interpretability
At first, richer split rules might sound less interpretable. A standard rule like age < 35 is easier to read than a symbolic expression.
But interpretability is not only about the simplicity of one node. It is also about the size and shape of the whole tree.
A standard tree may need many simple rules to approximate a boundary. SREDT may need one symbolic rule.
For example:
x_0 * x_1 < 0
is more complex than:
x_0 < 0
But it may be much simpler than a deep tree with many rectangular cuts trying to approximate the same XOR-like boundary.
So SREDT trades slightly richer node rules for potentially smaller trees and clearer global structure.
SREDT Variants
The paper studies three variants of the base method.
Pretrained SREDT (P-SREDT) initializes the symbolic expression population using equations learned from a recurrent neural network. The paper uses equations from the AI Feynman collection as the pretraining source. The idea is to start the search from expressions that are already mathematically meaningful, rather than purely random symbolic structures.
Lookahead SREDT (L-SREDT) evaluates a split not only by its immediate quality, but also by its effect one level deeper in the tree. This is inspired by lookahead search in decision trees. A split that looks slightly weaker now may lead to much better child splits.
Local SREDT adds local optimization for constants inside symbolic expressions. Before evaluating fitness, constants are optimized using a squared hinge loss. This helps the symbolic expression fit the split boundary more precisely.
These variants explore a practical question: can symbolic splits be made more stable, efficient, or accurate without losing the tree structure?
XOR Example
The XOR problem is a clean example of why axis-aligned trees can struggle.
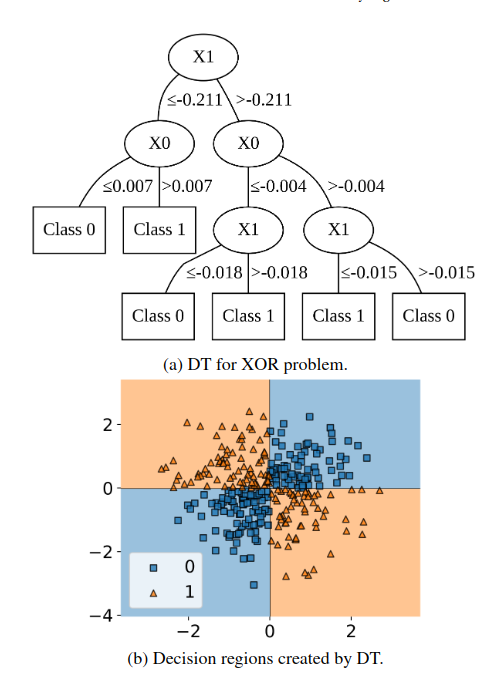
In XOR, the label depends on an interaction between two variables. A standard decision tree must carve the plane into rectangles.
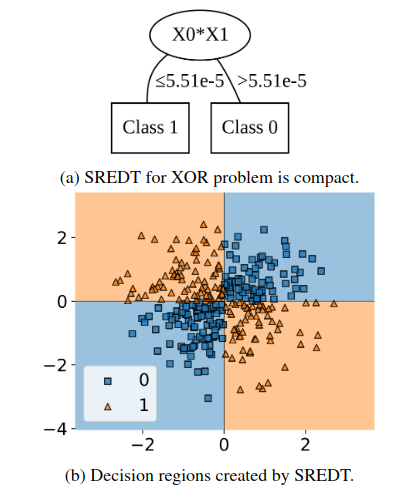
SREDT can search for expressions involving interactions between variables. If it discovers a useful expression such as a product term, it can separate the classes with fewer splits.
This is exactly the kind of case where symbolic regression helps: the important pattern is not one feature alone, but a relationship between features.
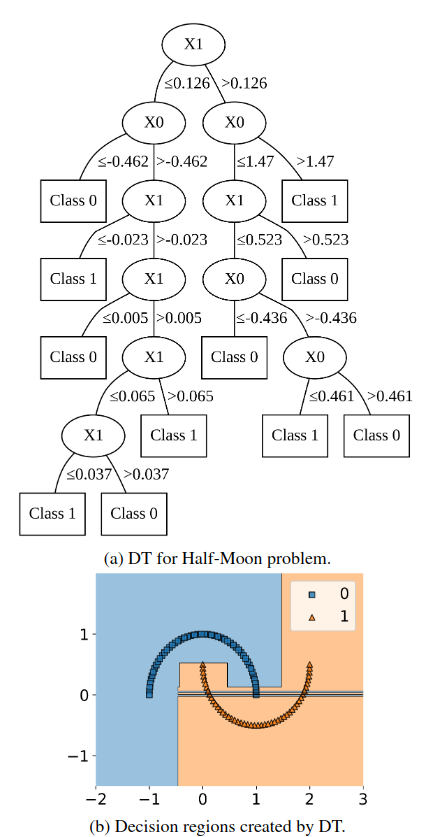
Half-Moon Example
The half-moon dataset shows another limitation of axis-aligned splits. The boundary is curved, so a standard tree approximates it through many rectangular regions.
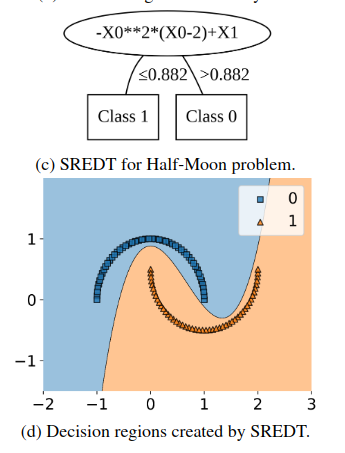
This illustrates the practical benefit: symbolic expressions can capture nonlinear structure that would otherwise require many tree nodes.
Experimental Results
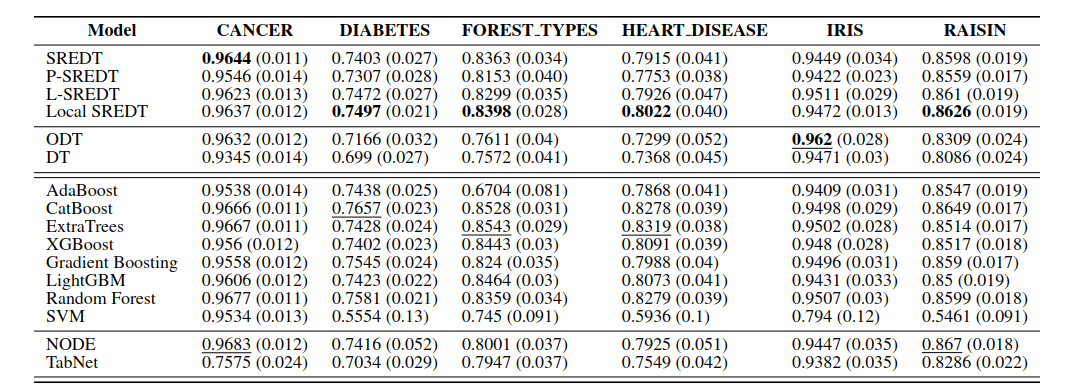
The paper evaluates SREDT variants against traditional models and deep models on six classification datasets. The results show that SREDT can be competitive while producing compact tree structures.
The main reported benefits are:
- higher accuracy and F-score compared with standard decision trees and oblique decision trees in the evaluated tasks
- smaller and more compact trees
- faster inference than some competing tree variants
- richer but still inspectable split rules
The key point is not that SREDT always replaces every classifier. The point is that symbolic split rules can improve the trade-off between accuracy, compactness, and interpretability.
Why This Is Neurosymbolic
SREDT is a good example of a neurosymbolic-flavored method even though it is not a deep neural architecture in the usual sense.
It combines:
- symbolic expressions as human-readable rules
- search and optimization from symbolic regression
- decision-tree structure for transparent classification
- data-driven learning to choose useful splits
The result is a model that learns from data while producing symbolic decision rules. This sits naturally near other work on interpretable trees, symbolic regression, and structured machine learning.
Limitations
SREDT also has trade-offs.
Symbolic regression can be computationally expensive because it searches over expression structures. The search space is large, and the result depends on the allowed operators, population size, mutation strategy, and fitness function.
Interpretability also depends on expression complexity. A compact expression such as x_0 * x_1 is readable. A long expression with many nested functions may be harder to understand than a standard decision tree.
There is also a risk of overfitting. Rich symbolic expressions can fit small patterns in the training data unless the search is regularized or constrained.
Finally, domain meaning matters. A symbolic expression is more useful when its terms make sense to a human. In some tabular datasets, feature names and transformations may not carry obvious semantic meaning.
Takeaway
Symbolic Regression Enhanced Decision Trees improve decision trees by changing the split search.
Instead of limiting each split to one feature and one threshold, SREDT lets symbolic regression discover expressions that combine features in useful ways. This can produce smaller trees, better nonlinear boundaries, and more expressive explanations.
The method is especially interesting because it does not abandon interpretability. It keeps the decision-tree structure, but gives each node a richer language for describing the boundary.
For problems where the class boundary depends on interactions, products, ratios, curves, or other symbolic relationships, SREDT is a strong idea:
let the tree stay interpretable, but let the split rules become smarter.
References
- Fong, K. S., and Motani, M. (2024). Symbolic Regression Enhanced Decision Trees for Classification Tasks. Proceedings of the AAAI Conference on Artificial Intelligence, 38(11), 12033-12042.