Decision trees are often described as interpretable models. That is partly true, but it is not automatic. A tree with hundreds of nodes, repeated tests, and long root-to-leaf paths can be technically readable while still being painful to explain.
The NeurIPS 2022 paper “Decision Trees with Short Explainable Rules” by Victor F. C. Souza, Ferdinando Cicalese, Eduardo Sany Laber, and Marco Molinaro focuses on a simple but important question:
When a tree explains a prediction, how many different attributes does that explanation actually use?
This is different from asking only how deep the tree is. Depth counts the number of tests along a path. Explanation size counts the number of distinct attributes used along that path. If a path tests the same feature multiple times, its depth may be large, but its explanation may still be compact. If a path tests many different features, the rule becomes harder to understand.
The paper proposes this explanation size as a measure of decision-tree interpretability and introduces an algorithm, SER-DT, designed to build accurate trees with shorter rules.
Why Depth Is Not Enough
Traditional decision-tree interpretability often focuses on depth. A shallow tree is easier to read because a user needs to answer fewer questions before reaching a prediction.
That is a useful metric, but it misses another part of human understanding: the number of concepts involved in the explanation. A rule with three conditions over three unrelated features can be harder to reason about than a rule with three conditions over one feature range.
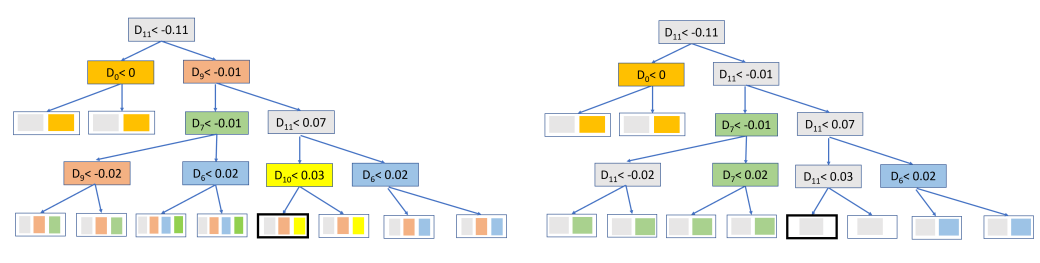
The Sensorless example from the paper makes this clear. CART and SER-DT produce trees with comparable accuracy, but the rules can be very different.
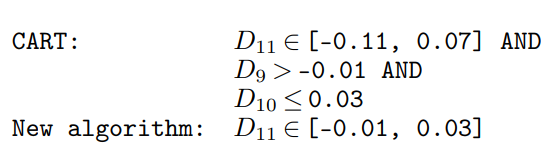
For one large leaf in the example, CART needs a rule involving D11, D9, and D10. SER-DT gives a rule using only D11. Both rules may lead to the same class, but the second one is much easier to communicate: the decision mostly depends on one attribute range.
That is the motivation for the paper. If the goal is explainability, we should care not only about how many tests a user follows, but also about how many distinct attributes the explanation asks them to understand.
Explanation Size
The paper works with threshold decision trees. Each internal node asks a question like:
Is attribute a less than threshold t?
The leaf reached by an object gives its predicted class. The depth of a leaf is the number of tests from the root to that leaf.
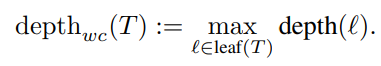
Worst-case depth is the maximum depth among all leaves. Average depth weights each leaf by how many examples reach it, or by how important those examples are.
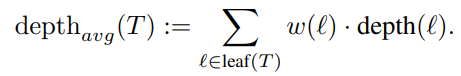
The new metric is explanation size. For a leaf, explanation size is the number of different attributes tested on the path from the root to that leaf.
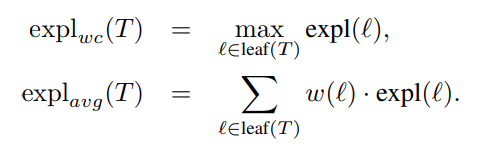
Here is the key distinction:
- Depth asks: how many questions must we answer?
- Explanation size asks: how many different attributes appear in the rule?
Both matter. A good explainable tree should avoid very long paths, but it should also avoid rules that jump across too many unrelated features.
The Trade-Off
The theoretical part of the paper studies whether it is possible to optimize both depth and explanation size at the same time.
At first, this seems unlikely. To make a tree shallow, an algorithm might need to use many different attributes quickly. To make explanations short, it might reuse the same attributes along a path, which could make the tree deeper.
The paper shows a more encouraging result: there exist trees that can preserve optimal explanation size while keeping depth close to optimal, up to logarithmic terms. The paper also proves that this kind of trade-off is essentially unavoidable. In other words, short explanations and shallow paths can be balanced, but one should not expect a perfect tree that optimizes every metric simultaneously in all cases.
For a practical reader, the main message is this: optimizing for short explanations is a real algorithmic objective, not just a cosmetic preference. It changes how the tree is built, and it can be studied with the same rigor as depth or tree size.
SER-DT: Short Explainable Rules Decision Tree
The authors propose an algorithm called SER-DT, short for Short Explainable Rules Decision Tree. Like other decision-tree algorithms, SER-DT recursively splits the data. Unlike CART, it explicitly cares about producing paths that use fewer distinct attributes.
The algorithm is built around the idea of separating examples that cannot share the same final leaf. If two examples have different classes and reach the same leaf, at least one of them must be misclassified. The paper calls such pairs misclassified pairs and uses the number of these pairs as a measure of how much classification work remains inside a node.
The algorithm tries to choose splits that reduce this remaining work while also controlling explanation size.

At a high level, SER-DT does the following:
- If all examples at the current node have the same class, create a leaf.
- Otherwise, look for a balanced test that reduces the weighted pairwise misclassification enough on both sides.
- If such a test exists, split on it and recurse.
- If not, choose an attribute and threshold that produce a useful three-way partition, implemented with two binary threshold tests.
- Continue recursively until the leaves are pure or a stopping rule is met.
The theoretical version gives approximation guarantees for both depth and explanation size. The practical version adds flexibility so that the method can compete with CART on real datasets.
How the Practical Version Chooses Splits
For experiments, the paper adapts the split selection using Gini impurity, the familiar criterion used by CART.
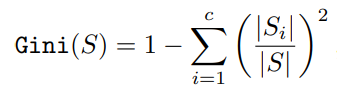
For a candidate split, weighted Gini impurity combines the impurity of the left and right children.
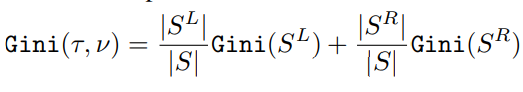
The important addition is a hyperparameter called FactorExpl. It controls how much the algorithm favors reusing an attribute that already appears on the current path.
The adjusted criterion is:
AdjustedGiniExpl(test, node) = I(test, node) * Gini(test, node)
where I(test, node) is:
FactorExplif the test uses an attribute already used on the path1if the test introduces a new attribute
Because the algorithm minimizes this adjusted score, a lower FactorExpl makes repeated attributes more attractive. That usually shortens explanations, but it may reduce accuracy if the model avoids a genuinely useful new attribute.
So FactorExpl becomes a practical accuracy-interpretability dial:
- lower values favor shorter explanations
- higher values behave more like standard Gini-based split selection
- values close to 1 can still reduce explanation size while keeping accuracy competitive
In the experiments, the authors use a maximum depth of 6 and prune sibling leaves when both predict the same class.
What the Experiments Show
The experiments use 20 real classification datasets. Each dataset is split into 70% training and 30% testing, and categorical features are converted with one-hot encoding.
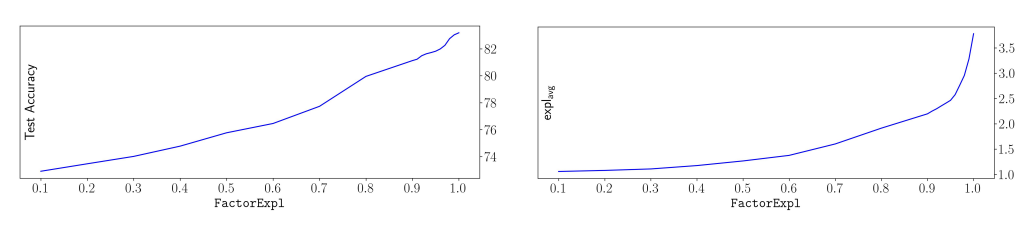
As expected, increasing FactorExpl tends to increase accuracy and explanation size. The useful finding is that accuracy grows slowly near high values of FactorExpl, while explanation size keeps growing. That suggests there is a practical region where the tree can become much more explainable with only a small accuracy cost.
The paper then compares SER-DT with CART using FactorExpl = 0.97.
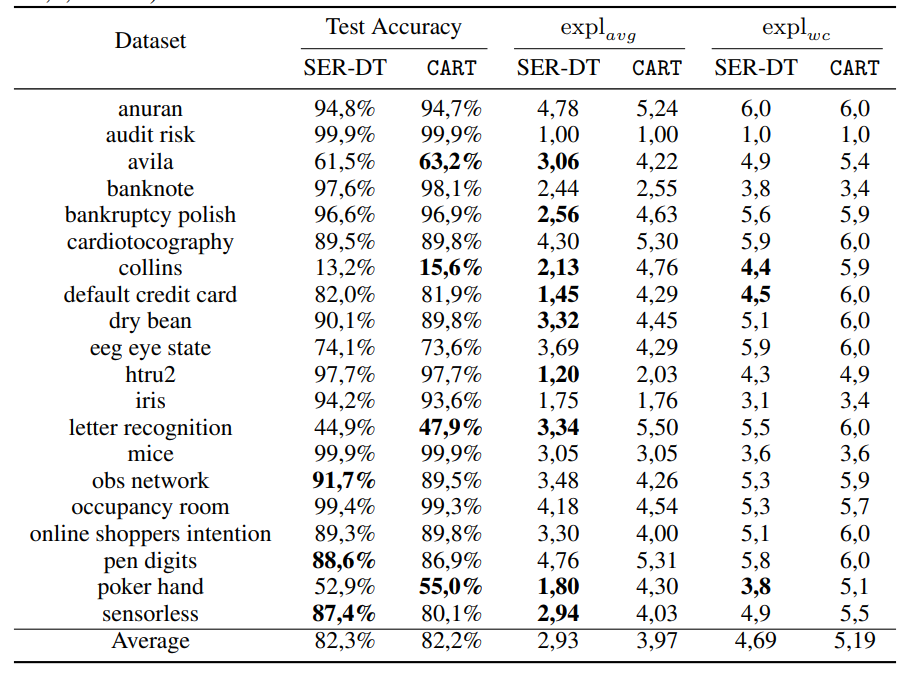
The average test accuracy is almost identical:
- SER-DT: 82.3%
- CART: 82.2%
But the explanation-size metrics improve:
- average explanation size drops from 3.97 with CART to 2.93 with SER-DT
- worst-case explanation size drops from 5.19 with CART to 4.69 with SER-DT
On average, SER-DT gives rules that mention fewer distinct attributes while keeping CART-like accuracy. The paper also reports that SER-DT performs at least as well as CART on average explanation size across all datasets, and improves it by at least 25% on 9 of the 20 datasets.
Why This Matters
Many explainability discussions stop at the surface: “decision trees are interpretable.” This paper is useful because it makes that statement more precise.
A tree is not explainable just because it is a tree. It becomes more explainable when its rules are short, stable, and conceptually simple. Explanation size captures one part of that simplicity: how many different attributes a user must consider to understand a prediction.
This matters in domains where explanations must be communicated to people who are not model builders. A credit analyst, doctor, operator, or auditor may not care that a model follows a tree path of depth 5 if that path involves 5 different signals. A rule based mostly on one or two attributes can be easier to check, challenge, and trust.
Limitations
Explanation size is a useful metric, but it is not the whole story.
A rule with one attribute can still be confusing if the attribute is hard to interpret. A rule with three attributes can be clear if those attributes are meaningful and naturally related. Also, reusing attributes can shorten explanations, but it may hide interactions that are genuinely important for accuracy.
There is also a modeling trade-off. If FactorExpl is pushed too low, the algorithm may over-prefer previously used attributes and miss better splits. The paper’s experiments suggest that values close to 1 can work well, but the right setting is still dataset-dependent.
Finally, the theoretical results assume an exact classification framing, while real-world machine learning often involves noisy labels, overlapping classes, and uncertain ground truth. The practical experiments address this partly, but deployment would still require validation on the specific application.
Takeaway
The main contribution of this paper is the idea that decision-tree explanations should be measured by the number of distinct attributes they use, not only by path length or tree size.
SER-DT shows that this idea can be turned into an algorithm. It keeps accuracy close to CART on the evaluated datasets while producing shorter, cleaner rules. For explainable AI, this is a valuable direction: instead of treating interpretability as a vague property, define what makes an explanation easier for humans and optimize for it directly.
References
- Souza, V. F. C., Cicalese, F., Laber, E. S., and Molinaro, M. (2022). Decision Trees with Short Explainable Rules. Advances in Neural Information Processing Systems, 35, 12365-12379.
Supplementary Materials
- Supplementary material: https://openreview.net/attachment?id=Lp-QFq2QRXA&name=supplementary_material
- GitHub repository: https://github.com/user-anonymous-researcher/interpretable-dts/tree/main
- SlidesLive talk: https://slideslive.com/38992387/decision-trees-with-short-explainable-rules?ref=search-presentations