Explainable AI is often treated as a technical problem: take a black-box model, compute feature importance, show a saliency map, or generate a counterfactual. Those tools are useful, but they are not the whole story.
The paper “Reasons, Values, Stakeholders: A Philosophical Framework for Explainable Artificial Intelligence” by Atoosa Kasirzadeh argues that AI explanations need a broader frame. If an AI system is used in a consequential decision, we should ask not only which features influenced the prediction, but also why this model was designed this way, why this data was used, what values shaped the system, and who needs the explanation.
That is the core idea behind the paper’s RVS framework: explanations should connect Reasons, Values, and Stakeholders.
The Nora Example
The paper uses a hiring example to make the problem concrete. Imagine Nora applies for a job. An AI system evaluates her CV and recommends rejecting her.
Nora asks a simple question: Why was I rejected?
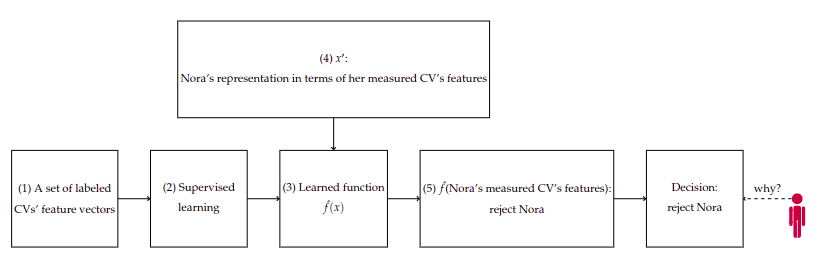
There are several possible explanations:
- The training data may not have represented candidates like Nora well.
- The learning process may have been supervised, optimized, or configured in a particular way.
- The model may have used a specific loss function, architecture, or reasoning style.
- Nora may have been represented through a narrow set of measurable features.
- Some of Nora’s measured features may have correlated with, caused, or counterfactually affected the rejection.
Most XAI methods focus on the fifth point. They tell us which features mattered for this one prediction. The paper argues that this is too narrow, especially for high-stakes decisions.
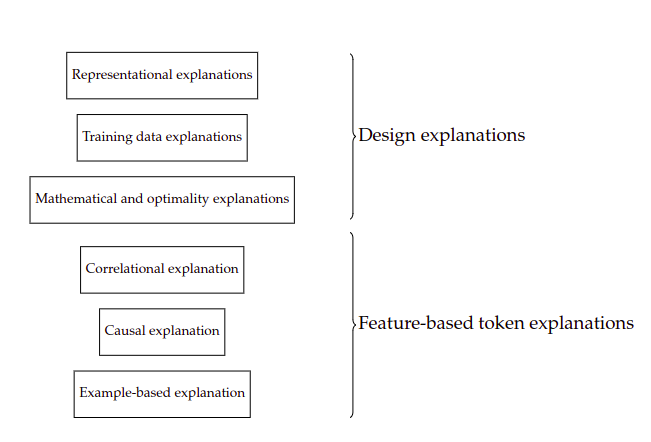
Feature-Based Token Explanations
Feature-based token explanations explain a particular prediction in terms of input features. These are the explanations most people associate with XAI.
The paper discusses three kinds.
Correlational explanations identify associations between input features and model outputs. Feature importance, saliency maps, partial dependence plots, individual conditional expectation, SHAP-style attributions, and rule extraction all fit into this broad family.
For Nora, a correlational explanation might say that previous job duration, education level, or employment gap contributed strongly to the rejection.
Causal and counterfactual explanations try to explain what caused the outcome or what would need to change for the outcome to change. A counterfactual explanation might say: “If Nora’s previous job duration had been two years longer, the system would have recommended an interview.”
These explanations can be powerful, but they require care. In social settings, it may be ethically or conceptually problematic to treat features such as ethnicity, gender, or disability as variables to manipulate.
Example-based explanations explain a decision by comparing it with similar cases. For example: “A candidate with a similar CV but longer job tenure was accepted.” These explanations are intuitive, but they depend heavily on which comparison class is chosen.
Feature-based explanations are useful because they speak directly to the prediction. But they do not answer everything. Nora may still ask: Why were these features collected? Why was this model used? Why should a statistical prediction decide a hiring outcome at all?
Design Explanations
The paper’s major contribution is to expand the space of XAI beyond feature attribution. It introduces design explanations: explanations that refer to how the AI system was built.
Design explanations include:
- mathematical and optimality explanations
- representational explanations
- training data explanations
These explanations are not always as simple as a feature-importance chart, but they often matter more for accountability.
Mathematical and Optimality Explanations
Machine learning systems are shaped by mathematical choices. A model is not just “learning from data” in a neutral way. It is optimizing an objective under a particular set of assumptions.
For example:
- What loss function is being minimized?
- What architecture is being used?
- What regularization is applied?
- What optimization method is used?
- What performance metric defines success?
- What trade-off is made between false positives and false negatives?
These choices partially explain the model’s output. If a hiring model is optimized to minimize early employee turnover, then candidates predicted to leave soon may be rejected. That optimization target is not just a technical detail. It shapes what the system treats as a good decision.
This is why mathematical and optimality explanations matter. They expose the reasoning style of the model. In sensitive domains, we should ask whether that reasoning style is appropriate in the first place.
Representational Explanations
Before a model can learn, the world must be represented as data. That step is never neutral.
For Nora, the system may represent her as a vector of features: years of experience, degree type, employment gap, job tenure, location, or assessment score. But Nora as a person is richer than that representation. The model can only reason over what has been measured and encoded.
A representational explanation asks:
- Why were these features chosen?
- What important qualities were left out?
- Can the target concept be measured accurately?
- Are the measurements socially or ethically appropriate?
- Do the features encode proxies for protected attributes?
This is especially important when AI is used for human decisions. Some qualities are difficult to quantify. Dignity, resilience, care work, contextual hardship, judgment, and lived experience may matter, but they may not fit cleanly into a feature vector.
If the representation is poor, even a technically accurate feature explanation may be misleading. The model can explain its output in terms of measured variables while ignoring the deeper question: whether those variables should have represented the decision problem at all.
Training Data Explanations
Training data explanations ask why the model learned what it learned.
Data has history. It reflects collection choices, institutional practices, social patterns, measurement decisions, missing groups, and past biases. If a dataset mainly includes successful candidates from one demographic background, the model may learn patterns that reproduce that history.
For Nora, a training data explanation might ask:
- Was the dataset large enough?
- Was it demographically inclusive?
- What labels were used to define “successful employee”?
- Were past hiring decisions biased?
- Were some groups underrepresented?
- What kinds of errors were considered acceptable?
The paper connects this to inductive risk: no model prediction is certain, and different types of error carry different social costs. In hiring, falsely rejecting a qualified candidate and falsely accepting an unqualified candidate do not have the same consequences for all stakeholders.
Choosing which errors matter more is not only a technical choice. It is also a value judgment.
Why Values Matter
The paper argues that explanations are not valuable merely because they are true or understandable. In high-stakes settings, explanations must also be evaluated through ethical and social values.
For example, suppose a model explains Nora’s rejection by saying that gender was an important feature. Even if that explanation is technically faithful, it is not acceptable if gender should not have been used in the decision.
This distinction is crucial:
- A faithful explanation tells us what the system did.
- A justifiable explanation tells us whether the system had acceptable reasons to do it.
XAI often focuses on the first. The RVS framework insists that we also need the second.
Values enter at many points:
- deciding which features exist and matter
- deciding how to measure them
- deciding which data to collect
- deciding which errors are tolerable
- deciding which optimization target is legitimate
- deciding who gets to challenge the system
An explanation that ignores these values can be technically impressive but socially incomplete.
Stakeholders Matter Too
Different stakeholders need different explanations.
A model developer may need mathematical and debugging information. An auditor may need access to training data assumptions, feature choices, and model behavior across groups. A decision subject such as Nora may need a local explanation of the rejection and a way to contest it. A policymaker may need to know whether the system should be used in hiring at all.
The paper expands the stakeholder set beyond technical roles. It includes computer scientists, operators, decision subjects, data subjects, examiners, policymakers, ethicists, philosophers, social scientists, and other critical observers.
This matters because AI systems often affect people who had no role in designing them. A democratic approach to XAI should make room for those affected by the system to question its assumptions, not just receive a simplified feature chart after the fact.
The RVS Framework
The RVS framework connects three things:
Reasons: the explanation types, including feature-based, mathematical, representational, and training-data explanations.
Values: the ethical, social, epistemic, and political assumptions that determine whether those reasons are acceptable.
Stakeholders: the people and institutions who need explanations for different purposes.
In this framework, XAI is not a single method. It is a structured conversation about why a model produced an output, whether that reasoning is acceptable, and who has the authority to evaluate it.
For low-risk systems, a minimal explanation may be enough. If an app classifies dog breeds for entertainment, a saliency map may be sufficient. But for hiring, healthcare, credit, welfare allocation, or criminal justice, a narrow feature explanation is not enough.
High-stakes AI requires broader explanation.
Practical Takeaways
When designing or evaluating an explainable AI system, ask more than “which feature mattered most?”
Ask:
- What data shaped the model?
- What was excluded from the data?
- What target was optimized?
- Which errors are most harmful?
- Which features should not be used?
- What assumptions are hidden in the representation?
- Who receives the explanation?
- Can affected people challenge the decision?
These questions do not replace technical XAI methods. They make those methods more meaningful.
Limitations
The RVS framework is broad, and that is both its strength and its challenge. It may be too heavy for simple applications. Not every model needs a full philosophical audit.
But the paper is not arguing that every AI system requires every explanation type in every context. The point is proportionality. The more consequential the decision, the more important it becomes to examine design choices, values, and stakeholders.
Another challenge is implementation. Translating RVS into product requirements, audit checklists, regulatory standards, or human-in-the-loop evaluations requires interdisciplinary work. Engineers, domain experts, ethicists, legal experts, and affected communities all have a role.
Takeaway
Explainable AI should not be reduced to feature attribution. Feature-based explanations are useful, but they are only one part of the picture.
Kasirzadeh’s RVS framework shows that good AI explanations must connect the technical reason for a prediction with the values embedded in the system and the stakeholders who need to understand or challenge it.
For high-stakes AI, the question is not only “Why did the model say this?”
The better question is:
“What reasons, values, and stakeholder needs make this prediction understandable, acceptable, or contestable?”
References
- Kasirzadeh, A. (2021). Reasons, Values, Stakeholders: A Philosophical Framework for Explainable Artificial Intelligence. arXiv:2103.00752.