Traditional decision trees grow in a very discrete way. A node is either a leaf or an internal decision node. During training, the algorithm decides to split a leaf, creates two children, and then moves on. Later, a separate pruning step may remove parts of the tree if they overfit.
The paper “Budding Trees” by Ozan Irsoy, Olcay Taner Yildiz, and Ethem Alpaydin, published at ICPR 2014, proposes a smoother version of this process. In a budding tree, a node can be a leaf and an internal decision node at the same time.
That sounds strange at first, but it gives the model a useful ability: a node can gradually grow children when they help, and gradually return to being a leaf when they do not. Growth and pruning become part of the same learning process.
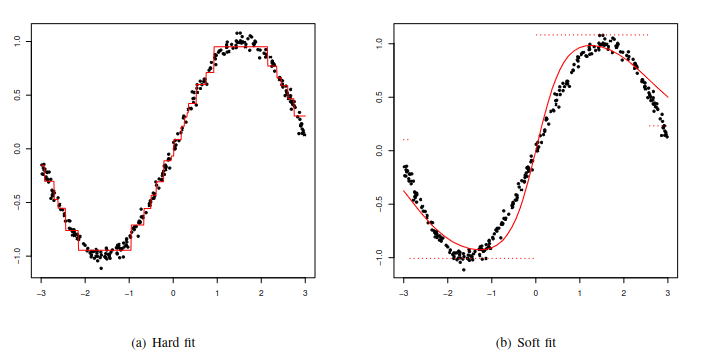
From Hard Trees to Soft Trees
A hard decision tree sends each input down exactly one path. At every internal node, the model applies a test and chooses either the left or right child.
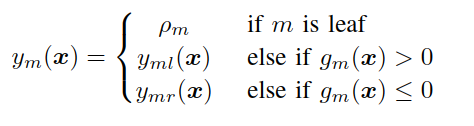
If the node is a leaf, it returns a stored response value. For regression, that value is numeric. For binary classification, it can represent the probability of the positive class.
Many classic trees use univariate splits, where a node tests one feature against a threshold.
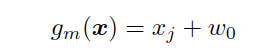
Multivariate trees generalize this idea by using a linear function of the input.
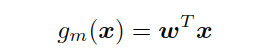
This creates oblique splits instead of axis-aligned splits. A univariate split cuts along one feature axis; a multivariate split can cut across a combination of features.
Soft decision trees change the routing rule. Instead of choosing only one child, the node sends the input to both children with weights determined by a gating function.
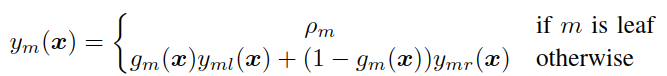
The gate is a sigmoid:
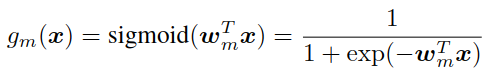
The value of the gate can be interpreted as the responsibility assigned to the left child, while 1 - g(x) is the responsibility assigned to the right child.
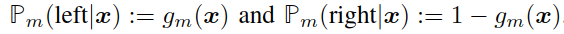
This is why soft trees often fit smooth regression functions better than hard trees. Even if the leaves store constant values, the soft gates blend the leaf responses and avoid abrupt jumps at split boundaries.
I discussed this foundation separately in Soft Decision Trees. Budding trees build directly on that idea.
The Budding Tree Idea
A budding tree adds one more soft quantity: leafness.
In a normal tree, a node is either a leaf or not. In a budding tree, every node has a parameter gamma, written as γ, that controls how leaf-like it is.
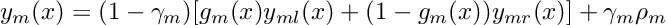
The response of a budding node combines two parts:
- a leaf response, controlled by
γ - a soft internal-node response, controlled by
1 - γ
If γ = 1, the node behaves like a pure leaf. Recursion stops there. If γ = 0, the node behaves like a pure internal soft decision node. If γ is between 0 and 1, the node is both: part leaf, part router.
This is the central idea of the paper. A node does not need to make a sudden jump from leaf to internal split. It can make that transition smoothly.
Why This Matters
Classic decision-tree induction is greedy. Once an upper split is chosen, later training usually treats it as fixed. If that early split was not ideal, the rest of the tree must work around it.
Budding trees take a different route. All parameters of all active nodes are updated together by gradient descent. A higher node can still change while lower nodes are being explored.
This gives the training process a kind of backtracking ability:
- a leaf can begin to grow by reducing its
γvalue - its children can start receiving responsibility and learning useful parameters
- if the split helps, the node becomes more internal
- if the split does not help, regularization can push
γback toward 1 - the node effectively becomes a leaf again
So budding trees combine growing and pruning in one continuous process.
Training Objective
For regression, the paper optimizes squared error plus a regularization term on γ.
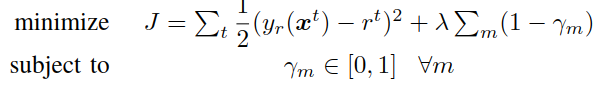
The first term measures prediction error. The second term penalizes nodes whose γ is below 1. Since γ = 1 means “this node is a leaf,” the regularizer pushes the tree toward simpler structures.
That regularization is important. Without it, the model could keep expanding nodes unnecessarily. With it, every split must earn its place by reducing prediction error enough to overcome the pressure toward leafness.
The optimization is constrained so that every γ stays between 0 and 1. If an update pushes γ outside that interval, the value is clipped back into the valid range.
Responsibilities and Gradients
The paper defines a responsibility signal for each node during stochastic gradient descent.
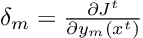
This responsibility tells the model how much a node contributes to the current error. The error is backpropagated from the root toward the leaves, similar in spirit to neural-network training.

The gradients update:
- the gate parameters
w - the response value
rho - the leafness parameter
gamma
This is where budding trees differ sharply from classic trees. Instead of fitting one local split while freezing the rest of the structure, the model updates the full active tree.
If an error signal suggests that a leaf cannot explain the data well, γ can decrease and the node starts behaving more like an internal node. The children then receive more responsibility and their parameters matter more. If the children do not improve the loss, regularization pushes γ back up and the children become irrelevant again.
The authors use an AdaGrad-style adaptive learning rate.
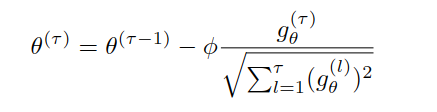
This is useful because nodes near the root receive updates more often than deeper nodes. Adaptive learning rates allow rare parameters, often deeper in the tree, to receive larger effective updates when they finally become active.
Classification Extension
The model extends naturally to classification.
For binary classification, the root output is passed through a sigmoid and interpreted as the probability of the positive class. The squared-error term is replaced by cross-entropy.
For multiclass classification, each leaf stores a vector of class scores instead of a single scalar. The same tree computes one score per class, and a softmax at the root converts those scores into class probabilities.
This makes the architecture usable for regression, binary classification, and multiclass classification with the same basic mechanism.
What Training Looks Like
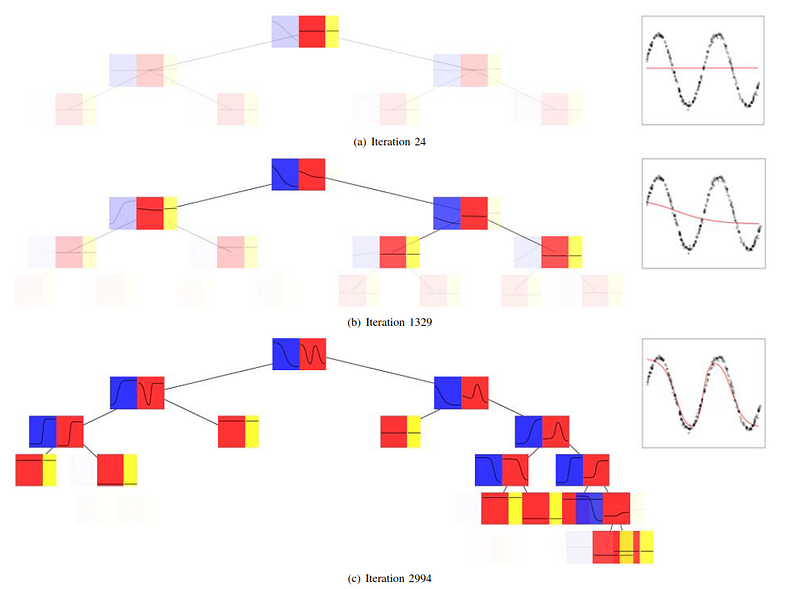
The training visualization in the paper shows the model becoming more structured over time. Early in training, many lower nodes exist but have little effect because their ancestors are still close to being leaves. As training continues, useful nodes move away from γ = 1, become more active, and allow their children to shape the response.
This is a helpful way to think about the model. Budding trees may physically contain nodes that are not yet meaningful. Their influence depends on the γ values along the path. A subtree can exist as a possibility before it becomes an important part of the prediction.
Experimental Results
The authors evaluate budding trees on regression, binary classification, and multiclass classification datasets from the UCI repository. They compare against hard C4.5 trees, linear discriminant trees, and soft decision trees.
For regression, budding trees perform strongly. Across ten regression datasets, the paper reports that budding trees achieve significantly smaller mean squared error except for two ties. Soft trees sometimes use fewer nodes, but budding trees often produce better approximation.
For binary classification, the results are more mixed. Budding trees win on two datasets, soft trees win on four, linear discriminant trees win on one, and three datasets are ties. The paper notes that on some smaller datasets, budding trees fit validation sets well but generalize less well to the test set.
For multiclass classification, budding trees perform particularly well. They significantly outperform C4.5 and linear discriminant trees on six of ten datasets, with one C4.5 win and three ties.
The overall picture is that budding trees are strongest when smooth, jointly trained structure helps: regression and several multiclass settings. They are not automatically superior on every binary classification dataset.
Advantages
Budding trees have several useful properties:
- they preserve the smooth routing advantages of soft decision trees
- they train tree structure and parameters jointly
- they allow a node to move gradually from leaf to internal node
- they incorporate pruning pressure during training
- they support regression, binary classification, and multiclass classification
- they can be trained with gradient-based optimization
The most important conceptual advantage is that training is no longer a one-way greedy construction. A budding tree can explore a split and then retract it.
Limitations
Budding trees also inherit some difficulties from differentiable models.
Gradient descent can get stuck in local minima. The model has more moving parts than a standard decision tree: gate weights, response values, and leafness parameters. Hyperparameters such as the learning rate and regularization strength matter.
Model size can also be tricky to compare. Because some nodes may have parents with γ very close to 1, the physical tree can contain subtrees that barely affect the output. The paper notes that these nearly inactive subtrees can often be pruned with negligible change in accuracy.
There is also an interpretability trade-off. A hard tree gives a crisp path. A budding tree gives a weighted, differentiable computation over soft gates and partial leaves. That is more flexible, but less straightforward to explain as a simple rule list.
Takeaway
Budding trees are not more expressive than soft decision trees in a strict representational sense. The authors point out that a budding tree can be converted into an equivalent soft tree. The real contribution is the training mechanism.
By introducing the leafness parameter γ, the paper turns tree growth into a continuous process. A node can start as a leaf, partially grow, become a useful internal decision node, or shrink back toward a leaf if the split is not helpful.
That makes budding trees an important step between classic decision-tree induction and differentiable tree learning. They keep the hierarchical structure of trees, but train more like neural models: with gradients, responsibilities, and continuous parameter updates.
References
- Irsoy, O., Yildiz, O. T., and Alpaydin, E. (2014). Budding Trees. 2014 22nd International Conference on Pattern Recognition, 3582-3587. IEEE.
- Irsoy, O., Yildiz, O. T., and Alpaydin, E. (2012). Soft Decision Trees. Proceedings of the 21st International Conference on Pattern Recognition, 1819-1822. IEEE.