Deep neural networks are powerful, but they are often hard to explain.
A neural network may classify an image correctly, but understanding why it made that decision can be difficult. The model’s internal representation is distributed across many layers and many units. A single hidden unit rarely has a clean, isolated meaning, and the final prediction usually depends on many weak statistical regularities acting together.
Decision trees have the opposite character. They are much easier to explain because a prediction follows a sequence of decisions. But decision trees usually do not generalize as well as deep neural networks, especially on high-dimensional data.
The paper “Distilling a Neural Network Into a Soft Decision Tree” by Nicholas Frosst and Geoffrey Hinton explores a useful compromise:
Can we use a neural network to train a more interpretable decision tree?
The answer is yes, with a tradeoff. The distilled soft decision tree is not as accurate as the neural network, but it performs better than a tree trained directly on hard labels and is much easier to inspect.
The Core Idea
The paper uses knowledge distillation.
Instead of training the decision tree only on the true labels, the authors first train a neural network. Then they use the neural network’s output probabilities as soft targets for training a soft decision tree.
This matters because soft targets contain more information than hard labels.
For example, a handwritten digit image may be labeled as 8, but a neural network may assign:
- 0.80 probability to
8 - 0.12 probability to
3 - 0.05 probability to
9 - small probabilities to other digits
That distribution tells the tree not only what the correct answer is, but also which classes are confusingly similar. This extra information helps the tree learn better decision boundaries.
Why Not Just Explain the Neural Network?
There are many methods for explaining neural networks, such as saliency maps, feature visualization, and local surrogate models. These methods are useful, but they often explain the model indirectly.
Frosst and Hinton take a different approach. Instead of explaining the neural network itself, they train a new model that behaves more like the neural network but has a more interpretable structure.
At test time, the soft decision tree is the model being used.
This gives a simpler explanation path: follow the decisions from the root of the tree to the selected leaf.
What Is a Soft Decision Tree?
A standard decision tree makes hard decisions. At each internal node, the input goes left or right.
A soft decision tree makes probabilistic decisions. Each internal node computes the probability of taking one branch or the other.
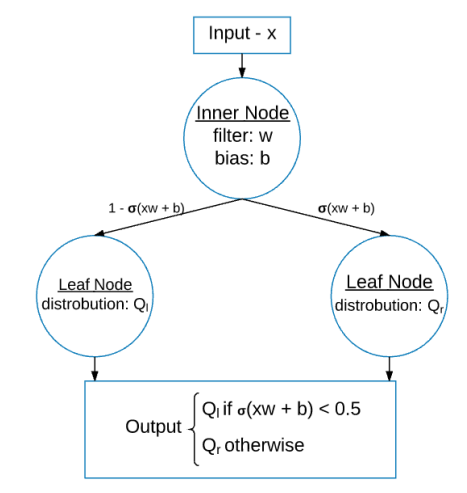
Each internal node has:
- a learned filter
w - a bias
b - a sigmoid decision function
The probability of taking the right branch is:
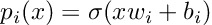
Here, x is the input and sigma is the sigmoid function.
The paper also introduces an inverse temperature parameter beta, which controls how sharp the decision is.
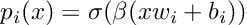
When beta is larger, the decision becomes closer to a hard left-or-right choice. When it is smaller, the decision is softer.
What Happens at the Leaves?
Each leaf stores a learned probability distribution over classes.
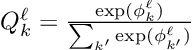
This is different from a normal tree where a leaf may simply store a class label. In a soft decision tree, a leaf can say something like:
- 70% class
8 - 20% class
3 - 10% class
9
This fits naturally with distillation because the teacher neural network also provides probability distributions, not just labels.
How the Tree Is Trained
Most decision trees are trained greedily. They choose a split at one node, then continue splitting lower nodes.
This paper trains the whole soft decision tree with mini-batch gradient descent. The size of the tree is chosen in advance, and all filters, biases, and leaf distributions are updated together.
The training loss minimizes the cross-entropy between the tree’s leaf distributions and the target distribution, weighted by the probability of reaching each leaf.

This gives the model a differentiable objective, which makes gradient-based training possible.
Avoiding Dead Branches
One practical problem with soft trees is that a node may learn to send almost all examples to one branch. If that happens too early, the unused branch receives little training signal and the tree can get stuck.
To reduce this problem, the authors add a regularization penalty that encourages internal nodes to use both subtrees.
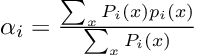
The full penalty is summed over internal nodes:

The paper also notes that this penalty should decay with depth. Near the root, balanced splits are often useful. Deeper in the tree, an uneven split may be natural because the node may only be responsible for a narrow subset of classes.
This is an important practical detail. Interpretability does not come only from drawing a tree; the tree must also be trained in a way that avoids degenerate behavior.
MNIST Results
The paper evaluates the method on MNIST.
A soft decision tree of depth 8 trained directly on true labels reached 94.45% test accuracy. A convolutional neural network reached 99.21%. When the soft decision tree was trained using soft targets from the neural network, it improved to 96.76%.
That result captures the main tradeoff:
- The distilled tree is worse than the neural network.
- The distilled tree is better than the tree trained directly on labels.
- The distilled tree is more interpretable than the neural network.

The visualization is the most interesting part of the paper. Internal nodes learn filters that separate meaningful groups of digits. For example, a node may learn to distinguish between digits that look like 3 and digits that look like 8.
This gives the model a kind of inspectable hierarchy. We can follow the path through the tree and see which visual distinctions influenced the final prediction.
Why This Is Useful
This method is useful when interpretability matters enough to accept some loss in accuracy.
Examples include:
- education tools that need to explain predictions
- medical or scientific decision support
- debugging neural network behavior
- model compression with interpretability
- safety-critical domains where explanations matter
- exploratory analysis of what a neural model has learned
The soft decision tree does not fully recover the performance of the neural network. But it gives a transparent approximation of the neural network’s behavior.
Relationship to Explainable AI
This paper is an early and elegant example of a broader explainable AI strategy:
Use a powerful black-box model as a teacher, then train a more interpretable model as a student.
The student model may not match the teacher perfectly, but it can inherit some of the teacher’s useful knowledge while remaining easier to inspect.
This differs from local explanation methods such as LIME, which build explanations around individual examples. A distilled tree is a global model. It can be inspected as a whole.
Limitations
The method has clear limitations.
First, accuracy drops compared with the neural network. If the application only cares about maximum predictive performance, the original neural model may be preferable.
Second, the tree size must be chosen. A shallow tree may be too simple, while a deep tree may become harder to interpret and more prone to overfitting.
Third, the learned filters may still require interpretation. The model is more interpretable than a deep neural network, but it is not automatically self-explanatory.
Fourth, the approach depends on the quality of the teacher model. If the neural network learns spurious patterns, the tree may inherit them.
Takeaway
Frosst and Hinton’s paper is valuable because it frames interpretability as a tradeoff, not a slogan.
Deep neural networks generalize well but are difficult to explain. Decision trees are easier to explain but often generalize poorly. Distilling a neural network into a soft decision tree gives a middle ground.
The resulting model is not perfect, but it is useful:
- it learns from the neural network’s soft targets
- it makes probabilistic hierarchical decisions
- it provides a path-based explanation for predictions
- it performs better than a tree trained only on hard labels
In short:
A soft decision tree lets us borrow some of a neural network’s knowledge while keeping a model structure that humans can inspect.
References
- Frosst, N., & Hinton, G. (2017). Distilling a Neural Network Into a Soft Decision Tree. arXiv:1711.09784.
- Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network. arXiv:1503.02531.
- Ribeiro, M. T., Singh, S., & Guestrin, C. (2016). “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. arXiv:1602.04938.