Some machine learning ideas are interesting because they perform well. Others are interesting because they make us rethink the shape of a model. Adaptive Neural Trees (ANTs), proposed by Tanno et al. at ICML 2019, fall into the second category.
The paper asks a simple but powerful question:
Can we build a model that learns features like a neural network, but makes conditional decisions like a decision tree?
That question matters because neural networks and decision trees solve different parts of the learning problem beautifully. Neural networks are excellent at representation learning: they transform raw data into useful internal features. Decision trees are excellent at conditional computation: for a given input, they follow only one path through the tree. ANTs try to bring these two strengths into one model.
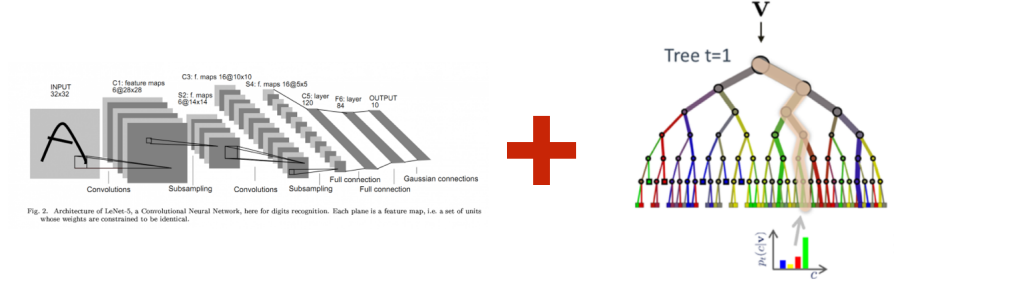
Why Combine Neural Networks and Decision Trees?
Deep neural networks have changed machine learning because they reduce the need for manual feature engineering. Given enough data and a well-designed architecture, they can learn layered representations that work for images, speech, language, forecasting, and many other tasks.
But they also come with two practical limitations:
- The architecture is usually designed manually before training.
- At inference time, every input typically activates the full network.
That second point is important. A large neural network may be very accurate, but each prediction can require a large amount of computation because the same full model is used for every sample.
Decision trees have a different personality. A tree learns a hierarchy of decisions, and each input follows a path from the root to a leaf. This makes inference lightweight because the model does not need to activate every branch. Trees can also adapt their structure to the data: if the problem needs more splits, the tree can grow.
However, classic decision trees usually rely on fixed or hand-designed features. Their split functions are often simple, which limits their expressiveness on complex data such as images.
ANTs are motivated by this tradeoff:
- Neural networks learn powerful features but often use fixed, heavy architectures.
- Decision trees adapt their structure and use conditional paths, but often lack rich feature learning.
Adaptive Neural Trees aim to get both.
The Core Idea
An Adaptive Neural Tree is a tree where the edges, internal nodes, and leaves are all neural modules.
Instead of asking a tree to split raw input features directly, ANTs allow the input to be transformed as it moves through the tree. Each path from the root to a leaf becomes a small neural network. At the same time, the tree structure decides which path is used for each input.

The model is built from three types of modules:
- Transformers sit on the edges and transform the representation. In image tasks, these can be convolutional layers followed by nonlinear activations.
- Routers sit at internal nodes and decide whether an input should move left or right.
- Solvers sit at the leaves and produce the final prediction.
This design is the main reason ANTs are interesting. The model is not just a decision tree wrapped around a neural network. The neural computation is distributed through the tree itself.
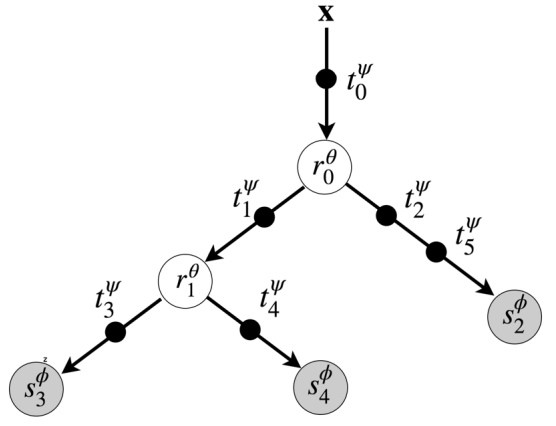
How an Input Moves Through the Tree
Think of an input image entering the root of the tree. It first passes through a transformer, which creates a learned representation. A router then looks at that representation and decides which branch should be followed. The process repeats until the input reaches a leaf node, where a solver produces the prediction.

The important detail is that routing is learned. The model is not using a manually written rule such as “if pixel intensity is greater than this value, go left.” Instead, the router can itself be a neural network that learns what information is useful for splitting the data.
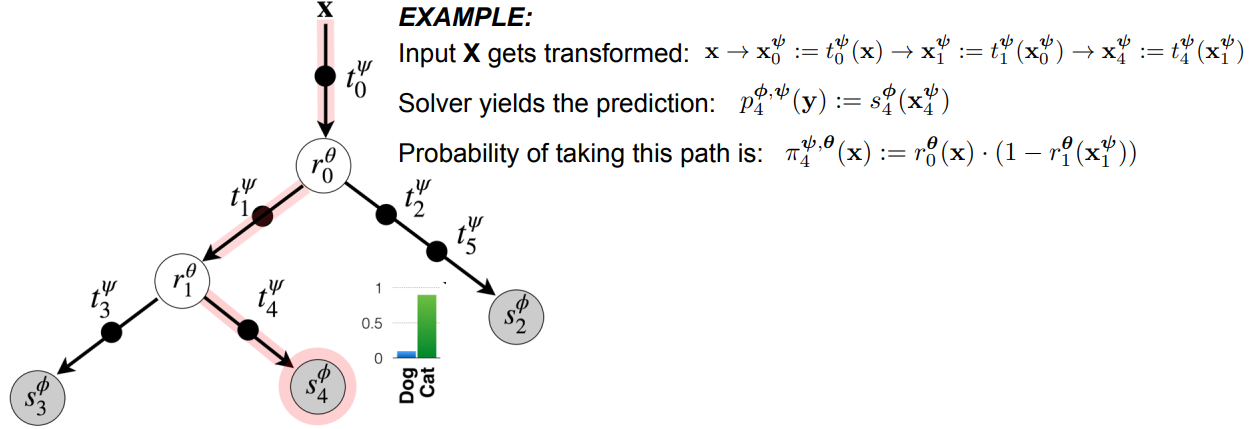
During inference, the paper discusses two ways to use the model:
- Multi-path inference, where predictions from multiple leaves are combined according to path probabilities.
- Single-path inference, where the model follows the most likely path and uses only the modules on that path.
Single-path inference is especially attractive because it gives the model conditional computation. Different inputs can activate different parts of the tree, and a prediction can be made without evaluating the whole model.
What Makes the Tree Adaptive?
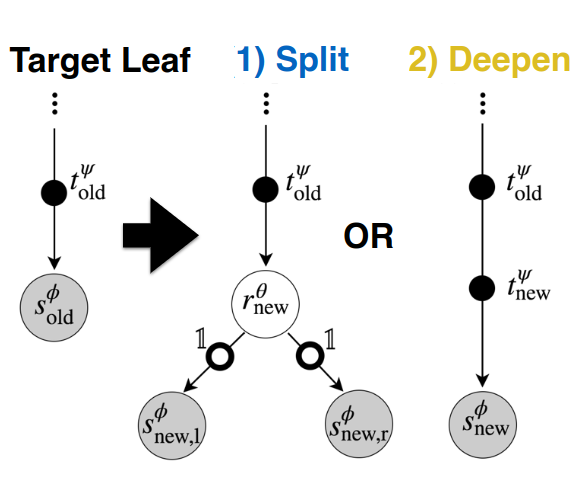
The word “adaptive” is doing real work here. ANTs do not require the full tree architecture to be specified in advance. The model starts from a simple structure and grows progressively.
At a candidate leaf, the training algorithm considers three options:
- Keep the current node as it is.
- Split the node by adding a router and two child leaves.
- Deepen the path by adding another transformer before the solver.
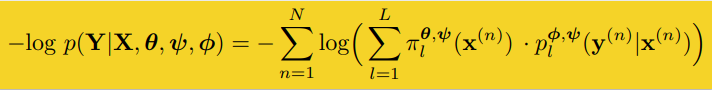
This is a useful way to think about the model’s decision process:
- If the data at a node contains different subgroups, splitting may help.
- If the data needs a richer representation, deepening may help.
- If neither improves validation performance, the model keeps the current structure.
The authors train the proposed alternatives locally, compare them using validation loss, and choose the best option. This process continues level by level until additional growth no longer helps.
After the growth phase, the model enters a refinement phase, where the full tree is optimized globally. This is important because greedy local decisions can be imperfect. Global refinement gives the model a chance to adjust the modules together.
In the paper, refinement often polarizes router decisions. In plain terms, some routes become clearly preferred while others become rarely used. That can effectively prune weak branches and improve generalization.
How ANTs Differ From Earlier Neural Trees
Many earlier models tried to combine neural networks and decision trees. The paper positions ANTs as a more complete version of this family.
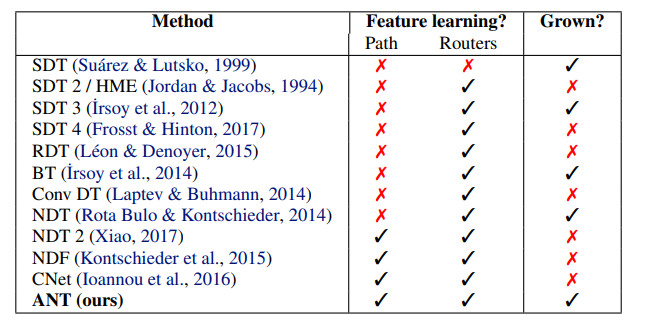
The difference is not just that ANTs use neural networks somewhere inside a tree. The key is that they satisfy three conditions at once:
- Each root-to-leaf path can perform neural feature learning.
- Routers can learn features for making routing decisions.
- The architecture can grow from primitive modules instead of being fully fixed in advance.
That combination is what allows ANTs to act like a bridge between neural architecture search, conditional computation, and differentiable decision trees.
Experiments: What Did the Paper Show?
The authors evaluate ANTs on three types of tasks:
- SARCOS, a multivariate regression dataset.
- MNIST, a handwritten digit classification dataset.
- CIFAR-10, a natural image classification dataset.

The results are not meant to show that ANTs beat every modern deep architecture. Instead, the paper makes a more nuanced point: a tree-structured neural model can remain competitive while using conditional computation and learning interpretable hierarchies.
On SARCOS, the strongest methods were tree-based, and ANTs achieved the lowest mean squared error when using the full model. This supports the idea that hierarchical partitioning can be very effective for regression tasks.
On MNIST, ANT variants achieved over 99% accuracy. One particularly interesting result is that a compact ANT achieved much better accuracy than a linear classifier while using roughly the same number of parameters during single-path inference. That is a strong demonstration of why tree-structured feature sharing can be useful.
On CIFAR-10, ANTs achieved over 90% accuracy and outperformed older tree-based methods such as deep forests. Larger architectures such as DenseNet still performed better, but they used many more parameters. The paper’s point is not “ANTs replace all CNNs”; it is that conditional, tree-shaped neural models can be accurate and efficient.
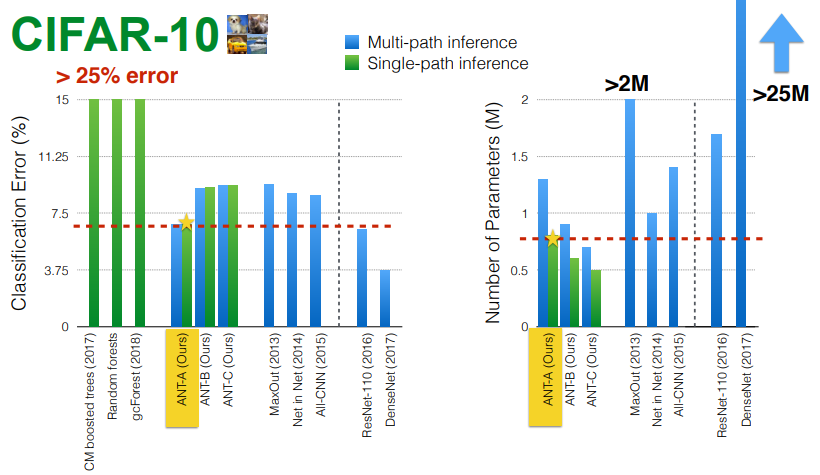
The Most Interesting Result: Learned Hierarchies
For me, the most engaging part of the paper is not just the accuracy table. It is the learned hierarchy.
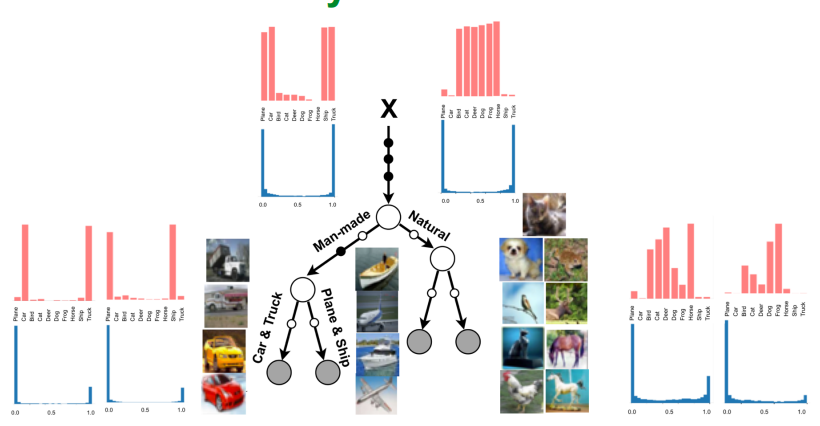
On CIFAR-10, the model discovers routing patterns that group semantically related classes. For example, it can separate natural objects from man-made objects, and then further separate vehicles from other categories. This is not because the authors manually told the model to use those groupings. The hierarchy emerges because those splits help the prediction task.
This point needs a careful interpretation. A learned tree is not automatically a perfect human explanation. The hierarchy is optimized for predictive performance, not for human readability. But the fact that useful semantic structure appears at all is valuable. It gives us a model that is not just a dense block of computation, but a conditional structure we can inspect.
Why Refinement Matters
The growth phase builds the tree using local decisions. That is efficient, but local decisions can create branches that later turn out to be unnecessary. The refinement phase helps correct this.
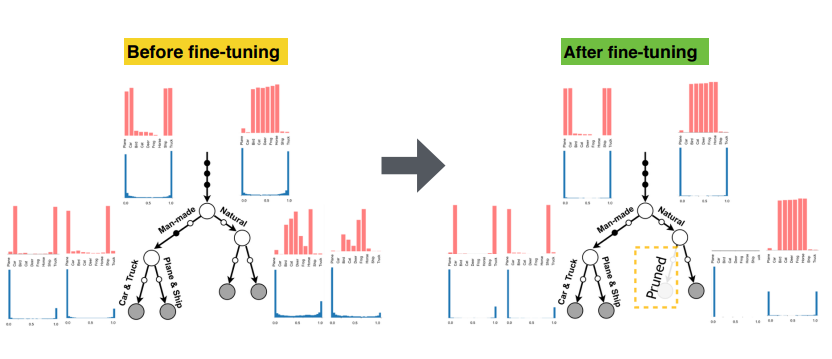
In the paper’s CIFAR-10 analysis, refinement improves generalization and can make some routing probabilities close to zero or one. When a branch is rarely visited after refinement, it becomes a candidate for pruning. This is one of the cleanest connections between decision-tree behavior and neural optimization in the paper: the model can grow, specialize, and then simplify.
Why This Paper Still Feels Relevant
Adaptive Neural Trees are from 2019, but the questions they raise are still current:
- How can models use computation conditionally instead of activating everything for every input?
- How can architectures adapt to dataset size and complexity?
- How can we build models that are accurate but still inspectable?
- How can neural networks move beyond fixed monolithic designs?
These questions appear today in mixture-of-experts models, dynamic routing, neural architecture search, sparse computation, and efficient inference. ANTs are a useful paper to read because they connect those ideas through a familiar structure: a tree.
Limitations
There are also limitations worth keeping in mind.
First, the training process is more complex than training a standard feed-forward network. The model alternates between local growth decisions and global refinement, which adds engineering overhead.
Second, greedy growth can still make suboptimal decisions. Refinement helps, but it does not guarantee that the final tree is globally optimal.
Third, while ANTs are interpretable compared with a plain dense neural network, they are still neural models. A learned router or transformer is not as transparent as a simple hand-written decision rule.
Finally, the strongest modern CNN and transformer architectures can outperform ANTs on large vision benchmarks. The value of ANTs is not only raw accuracy; it is the combination of accuracy, conditional computation, adaptive structure, and inspectable hierarchy.
Takeaway
Adaptive Neural Trees are a thoughtful attempt to combine two modeling cultures:
- the representation learning culture of neural networks, and
- the conditional structure culture of decision trees.
The result is a model where each input can follow its own learned path, where the architecture can grow based on validation performance, and where the learned tree can reveal meaningful structure in the data.
The broader lesson is simple: model architecture does not have to be a fixed pipeline through which every input travels in exactly the same way. Sometimes a model should decide not only what to predict, but also which computation is worth using for a particular input.
References
- Tanno, R., Arulkumaran, K., Alexander, D. C., Criminisi, A., & Nori, A. (2019). Adaptive Neural Trees. Proceedings of the 36th International Conference on Machine Learning, PMLR 97, 6166-6175.
- Adaptive Neural Trees code repository: https://github.com/rtanno21609/AdaptiveNeuralTrees