Large language models and multimodal models can answer many questions, but multi-step reasoning remains difficult. The challenge becomes even harder when the task combines text and images, requires external knowledge, and needs several intermediate decisions before the final answer.
Dong, Zhang, Deng, Zhu, Dou, and Wen propose AR-MCTS, a framework for progressive multimodal reasoning through active retrieval and Monte Carlo Tree Search. The central idea is that a model should not reason in one blind pass. It should retrieve useful information as needed, explore possible reasoning paths, and learn from step-level rewards.
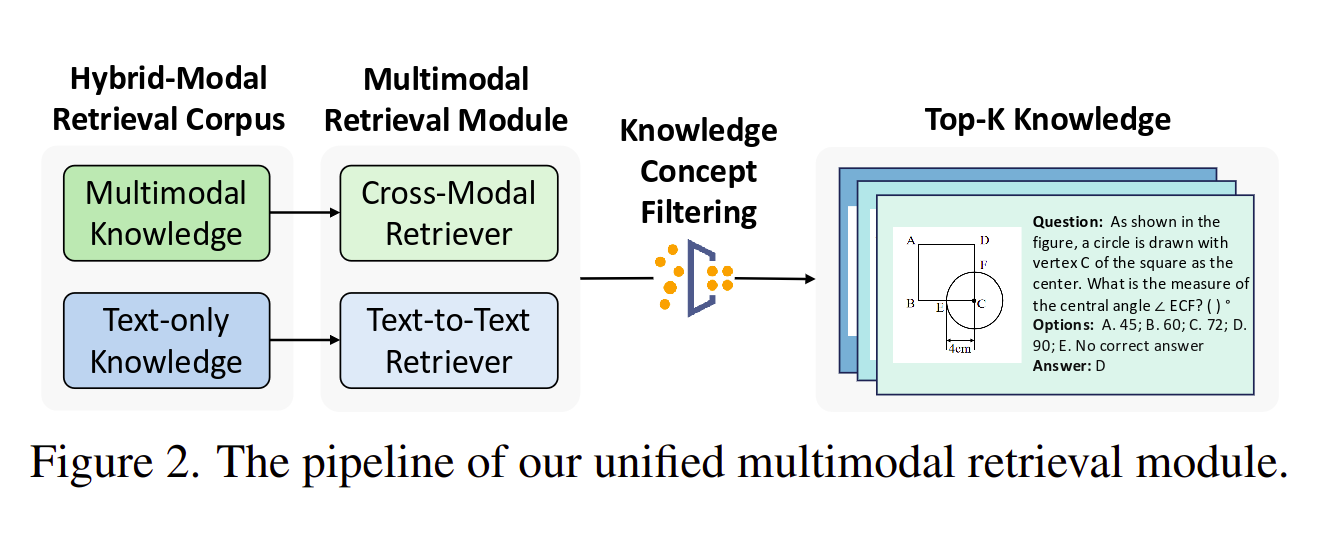
Why Reasoning Needs Retrieval
Many reasoning failures happen because the model lacks the right information at the right step. A multimodal model may understand the image and the question, but still need background facts, definitions, formulas, or contextual evidence.
Active retrieval addresses this by pulling relevant knowledge during the reasoning process, not only before the process begins. The model can retrieve information step by step as the problem unfolds.
This is closer to how people solve hard problems. We inspect the question, identify what we do not know, look up useful information, update our reasoning, and continue.
Why Use Monte Carlo Tree Search?
Monte Carlo Tree Search is a search method that explores possible decision paths and allocates more effort to promising branches. It has been successful in games and planning because it balances exploration and exploitation.
In AR-MCTS, each reasoning path can be treated like a branch in a tree. The model can explore different intermediate steps, evaluate them, and continue expanding the most promising ones.
This helps avoid one-shot reasoning errors. Instead of committing to the first generated chain of thought, the framework samples and evaluates multiple paths.
The AR-MCTS Loop
The framework combines three components:
- Active retrieval, which fetches relevant multimodal or textual evidence.
- Monte Carlo Tree Search, which explores multiple reasoning paths.
- A process reward model, which scores intermediate reasoning steps.
The process reward model is important because final-answer supervision is often too weak. If the final answer is wrong, we still need to know which step failed. If the final answer is right, we need to know whether the reasoning path was actually reliable.
By scoring intermediate steps, the framework can guide the search toward better reasoning trajectories.
What Improves
The paper reports improved performance on complex multimodal reasoning tasks. The gains come from a combination of better retrieval, broader exploration, and step-level evaluation.
Active retrieval improves grounding. MCTS improves search over possible reasoning paths. Process rewards improve training signals and help the model learn which intermediate steps are useful.
Together, these components reduce the dependence on manually written reasoning annotations and make the model more capable of building solutions progressively.
Why This Matters for Explainability
AR-MCTS is not just about accuracy. It also makes reasoning more inspectable.
When a system retrieves evidence and explores reasoning steps, there is a richer trace to examine. A human can inspect what information was retrieved, which path was selected, and where the model may have gone wrong.
This does not automatically solve explainability, but it gives better material for explanation than a single opaque answer.
Applications
The framework is relevant to tasks that require visual and textual reasoning together.
In education, it can help solve math, science, and diagram-based problems step by step. In healthcare, similar ideas could support reasoning over images and clinical text, though high-stakes use would require rigorous validation. In search and question answering, active retrieval can improve evidence-grounded responses.
The broader principle is useful beyond multimodal benchmarks: models should retrieve when uncertain, search over alternatives, and evaluate intermediate reasoning.
Limitations
AR-MCTS is more computationally expensive than a single forward pass. Retrieval, tree search, and reward scoring all add cost.
The method also depends on retrieval quality. If the external knowledge base is incomplete, noisy, or biased, the reasoning process can still fail. The reward model can also introduce errors if it scores polished but incorrect reasoning too highly.
These limitations are practical, not fatal. They show that better reasoning often requires more structured computation than simple generation.
Final Thoughts
AR-MCTS is a useful step toward more deliberate AI reasoning. It combines external knowledge, search, and step-level feedback so the model can reason progressively rather than guessing in one pass.
The key lesson is that complex reasoning should be treated as a process. For difficult multimodal tasks, the model needs to ask what information is missing, retrieve it, explore alternatives, and evaluate each step before answering.
That makes AR-MCTS an important direction for building AI systems that are not only more accurate, but also easier to inspect and debug.
References
- Dong, G., Zhang, C., Deng, M., Zhu, Y., Dou, Z. and Wen, J.R., 2024. Progressive Multimodal Reasoning via Active Retrieval. arXiv:2412.14835. https://arxiv.org/abs/2412.14835
- Hugging Face paper page. https://huggingface.co/papers/2412.14835
- Browne, C.B. et al., 2012. A Survey of Monte Carlo Tree Search Methods. IEEE Transactions on Computational Intelligence and AI in Games, 4(1), pp. 1-43. https://doi.org/10.1109/TCIAIG.2012.2186810