Origin-destination flow estimation sounds simple: find out where trips start, where they end, and how those trips change over time. In practice, it is one of the hardest problems in transportation modeling.
The reason is straightforward. We rarely observe every traveler from origin to destination. Instead, we observe fragments: traffic counts, speeds, sensors, surveys, GPS traces, mobile phone samples, toll records, or partial trajectories. From those fragments, we try to reconstruct a full OD matrix.
Krishnakumari, van Lint, Djukic, and Cats describe this challenge clearly in their work on data-driven OD matrix estimation. The problem is not only that data is incomplete. It is that the OD estimation problem is severely underdetermined, especially in large congested networks.

What an OD Matrix Represents
An OD matrix describes travel demand between zones. Each cell answers a basic question: how many trips moved from origin zone i to destination zone j during a given time period?
For a small network, this may sound manageable. But if a city has hundreds or thousands of zones, the number of possible OD pairs grows quickly. A model with 1,000 origins and 1,000 destinations has one million OD pairs for each time interval.
Now add time. Morning peak, midday, evening peak, and fine-grained intervals all change the OD pattern. A dynamic OD matrix can become enormous.
That is why the problem is underdetermined. There are far more unknown OD flows than there are observations to constrain them.
Why Counts Are Not Enough
Traffic counts are useful, but they are not the same as demand.
A loop detector or road sensor can tell us how many vehicles passed a location. It usually cannot tell us where those vehicles came from, where they are going, or how many alternative route choices produced the same count.
In uncongested networks, counts can sometimes be related more directly to OD flows through assignment matrices. But congestion changes the relationship. Downstream counts may reflect bottleneck capacity rather than the actual demand trying to enter the network.
That is a major issue. If a road is saturated, the number of vehicles observed downstream may be limited by capacity, not by how many travelers wanted to use that route. In that case, a traffic count is no longer a clean measurement of demand.
Two Ways to Think About OD Estimation
There are two broad approaches to OD estimation.
The first is forward demand modeling. This approach starts from activity patterns, land use, population, employment, trip purposes, and behavioral assumptions. It asks where trips should be produced and attracted based on how people live and move.
The second is reverse engineering. This approach starts from observed traffic data and tries to infer the OD matrix that could have produced those observations after network assignment.
Most practical OD estimation work blends both ideas. A prior OD matrix may come from surveys, planning models, or historical data. Observed traffic conditions are then used to update or adjust that prior.
The General OD Estimation Form
Many OD estimation methods can be written as an optimization problem.
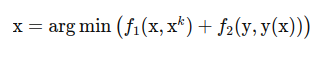
The model tries to estimate an unknown OD matrix x. It balances two goals:
- Stay close to a prior OD matrix.
- Reproduce observed traffic data as well as possible.
The first term measures how different the new estimate is from the prior matrix. The second term measures how well the estimated OD matrix explains observed traffic data such as counts or speeds.
This balance is necessary because observations alone are usually insufficient. Without a prior or regularization, many different OD matrices could match the same traffic counts.
Why the Choice of Error Metric Matters
The distance between the estimated OD matrix and the prior is often measured with simple metrics such as squared error or RMSE. These are easy to optimize, but they may not preserve the structure of the OD pattern.
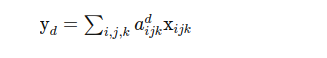

For OD matrices, structure matters. Two matrices may have similar RMSE but very different spatial or temporal patterns. A model can get many small values roughly right while missing the actual commute corridors, peak spreading, or directional flows that planners care about.
This is why some researchers argue for similarity measures that preserve structural patterns, not only pointwise numerical accuracy.
Observational Assumptions
OD estimation depends heavily on what we assume about observations.
Some observations are direct or close to direct. Travel surveys, license plate matching, automatic vehicle identification, GPS trajectories, and mobile phone traces may provide sampled OD information. These can help build a prior OD matrix.
But even direct samples have problems. They may be biased, sparse, privacy-limited, or uneven across user groups. A GPS sample may overrepresent certain travelers. A mobile phone dataset may not perfectly identify trip ends. A survey may be too small or outdated.
Other observations are indirect. Link counts, speeds, densities, and travel times reflect network conditions, not OD demand itself. They can provide useful clues, but their relationship to OD flows depends on route choice, congestion, bottlenecks, incidents, and assignment assumptions.
This is where OD estimation becomes difficult. We are not simply filling in missing values. We are inferring a hidden demand pattern from noisy and partial evidence.
Modeling Assumptions
Many traditional methods use a traffic simulation or network loading model to connect OD demand to observed traffic states.
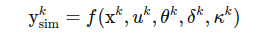

The simulation model takes OD flows as input and produces traffic conditions as output. In principle, we can search for the OD matrix that makes the simulated traffic match observed traffic.
The difficulty is that traffic simulation is complex and nonlinear. Small changes in OD demand can create large changes in congestion. Route choices can shift. Queues can spill back. Bottlenecks can form. Travel times can change dynamically.
Many approaches also assume some form of equilibrium, meaning travelers distribute themselves across routes in a stable way according to travel times or perceived costs. But in real traffic networks, equilibrium is hard to verify. Travelers have imperfect information, habits, preferences, timing constraints, and different levels of rationality.
So the model may work mathematically while relying on assumptions that are difficult to prove empirically.
Algorithmic Assumptions
Sequential estimation methods, such as Kalman filter variants, are often used for dynamic OD estimation.
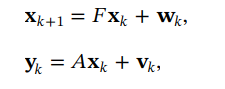
These methods describe OD flows as a state that evolves over time. The state equation predicts the next OD matrix from the previous one. The observation equation links the OD state to traffic measurements.
This is elegant, but it comes with assumptions. The process may be assumed linear or approximately linear. Noise terms may be assumed independent, zero-mean, and Gaussian, with known covariance matrices.
Those assumptions make the mathematics tractable, but traffic systems are rarely so clean. Demand shocks, incidents, weather, events, road closures, and behavioral changes can create non-Gaussian and nonlinear effects.
Why Congestion Makes Everything Harder
Congestion is the main reason OD estimation becomes much harder than a simple inverse problem.
In uncongested conditions, travel demand and observed flows are more directly connected. Vehicles move through the network without major delays, so counts and travel times can be interpreted more easily.
In congested conditions, the network itself distorts what we observe. A bottleneck can hold back vehicles. A queue can spill into upstream links. Drivers may reroute. A downstream sensor may show capacity flow even though hidden demand is much higher.
This means the same observed traffic pattern may be compatible with multiple OD patterns. Without strong assumptions or richer data, the true demand remains ambiguous.
The Data-Driven Alternative
Krishnakumari and coauthors propose a data-driven framework that uses supply patterns, such as speeds and flows, instead of relying on iterative dynamic network loading and equilibrium assignment.
Their method aims to estimate production and attraction time series from observed 3D supply patterns, using dimensionality reduction techniques such as principal component analysis. The approach reduces the dependence on assumptions about equilibrium route assignment.
This is valuable because it shifts the problem from “simulate the whole network until it matches observations” toward learning patterns directly from data.
The paper argues that the minimal ingredients are:
- A method to estimate or predict production and attraction time series.
- A method to compute
Nshortest paths from each OD zone. - Assumptions about the number of paths and proportionality of path flows.
This does not eliminate assumptions, but it changes which assumptions are required.
Why This Matters for Advanced Air Mobility
OD estimation is not only a road-traffic problem. It is also central to Advanced Air Mobility demand modeling.
If planners want to estimate air taxi demand, regional air mobility demand, airport shuttle demand, or vertiport placement, they need to understand where trips begin and end. Poor OD estimates can lead to poor infrastructure decisions: vertiports in the wrong places, oversized fleets, underused routes, or missed demand corridors.
For AAM, the challenge is even greater because future air mobility trips are not directly observed. Analysts often infer potential demand from taxi trips, airport trips, commuting flows, travel surveys, mobile data, or regional travel models. That makes the OD estimation assumptions even more important.
Final Thoughts
Traffic OD estimation is hard because the thing we want to know is mostly hidden. We observe pieces of the system, but not the full movement of every traveler across space and time.
The core difficulties are clear:
- The number of OD flows is much larger than the number of observations.
- Counts and speeds do not directly reveal demand, especially under congestion.
- Priors are necessary but can be biased or outdated.
- Simulation models depend on behavioral and equilibrium assumptions.
- Sequential algorithms depend on noise and linearity assumptions.
- Dynamic OD patterns change over time.
The best OD estimation methods are honest about those limitations. They combine data, models, priors, and validation carefully instead of pretending the inverse problem is simple.
For transportation planning, that honesty matters. OD matrices shape decisions about roads, transit, pricing, air mobility, infrastructure, and policy. If the demand estimate is wrong, the downstream decisions can be wrong too.
References
- Krishnakumari, P., van Lint, H., Djukic, T. and Cats, O., 2020. A data driven method for OD matrix estimation. Transportation Research Part C: Emerging Technologies, 113, pp. 38-56. https://doi.org/10.1016/j.trc.2019.05.014
- ScienceDirect record. https://www.sciencedirect.com/science/article/pii/S0968090X18317388
- TU Delft research portal. https://research.tudelft.nl/en/publications/a-data-driven-method-for-od-matrix-estimation