Large language models contain a huge amount of useful knowledge, but most of it is hidden inside model weights. We can prompt the model and observe its outputs, but the knowledge itself is not stored in a form that is easy to inspect, verify, reuse, or reason over.
Symbolic knowledge distillation tries to solve that problem. Instead of only compressing a large model into a smaller neural model, it aims to extract knowledge into more explicit forms: rules, facts, rationales, logic statements, knowledge graphs, semantic frames, structured datasets, or other symbolic representations.
This makes symbolic distillation especially important for large language models. LLMs are powerful, but they are expensive, opaque, and sometimes unreliable. If we can distill part of their knowledge into structured forms, we can build systems that are smaller, more interpretable, and easier to validate.
Why Symbolic Distillation Matters
Traditional knowledge distillation usually transfers behavior. A student model learns to imitate a teacher model’s outputs, features, or internal relationships. That is useful for compression, but it does not necessarily make the teacher’s knowledge understandable.
Symbolic distillation asks for something different: can we turn the teacher’s implicit knowledge into explicit knowledge?
For example, instead of only training a smaller model to copy an LLM’s answer, we might extract:
- A rule such as “if a medication interacts with another drug, flag the combination for review.”
- A factual triple such as
(Paris, capital_of, France). - A causal relation such as “blocked exits increase evacuation risk.”
- A reasoning trace explaining how a conclusion follows from evidence.
- A structured dataset of questions, answers, rationales, and constraints.
These artifacts can be inspected by humans, checked against external sources, and reused in smaller models or symbolic reasoning systems.
The Basic Pipeline
The symbolic distillation process usually begins with a carefully designed prompt. The prompt asks the teacher LLM to generate a specific type of knowledge: facts, explanations, rules, examples, summaries, comparisons, or reasoning steps.
The generated text is then processed. Natural language processing tools such as named entity recognition, dependency parsing, relation extraction, or semantic parsing can help identify entities, relationships, and claims. The output may then be converted into a structured representation such as a knowledge graph, rule base, table, or training dataset.
The final step is validation. This is critical. LLMs can produce plausible but incorrect knowledge, so symbolic outputs must be filtered, scored, checked, or reviewed. Validation may involve human experts, automated critics, natural language inference models, retrieval from trusted sources, consistency checks, or benchmark evaluation.
The result is not just a smaller model. It is a knowledge artifact that can support training, reasoning, explanation, or decision-making.
Direct Distillation
Direct distillation is the simplest version of symbolic knowledge distillation. A large teacher model is prompted to produce knowledge directly, and that knowledge is extracted, filtered, and stored.
The teacher might be asked to generate commonsense facts, domain-specific rules, question-answer pairs, explanations, or structured statements. The prompt design matters because vague prompts produce vague knowledge. Good prompts specify the domain, format, level of detail, and quality expectations.
Once the teacher generates responses, the outputs are converted into a usable form. This might involve parsing the response into triples, extracting rules, formatting examples into a dataset, or building a knowledge base.
The distilled knowledge can then be reviewed by humans or scored by a critic model. A critic model such as RoBERTa or another classifier can help filter outputs for relevance, coherence, factuality, or acceptability.
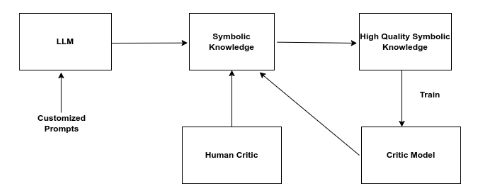
The strength of direct distillation is speed. It can produce useful symbolic knowledge quickly without training a complex pipeline first.
The weakness is quality control. If the teacher hallucinates or the prompt is underspecified, the resulting symbolic knowledge may be noisy. Direct distillation works best when paired with strong filtering and validation.
Multilevel Distillation
Multilevel distillation adds iteration. Instead of generating symbolic knowledge once, the system repeatedly generates, filters, trains, and refines.
The process begins with a large teacher model that produces an initial knowledge base or dataset. That output is filtered for quality. A smaller student model is then trained on the filtered data. The student generates new outputs, which are again filtered. The cycle repeats, gradually improving the student and the distilled dataset.
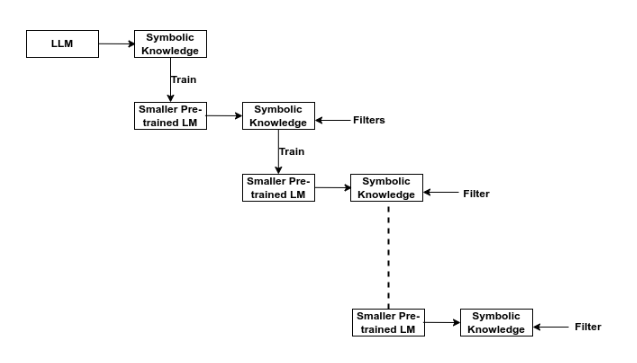
Several filters can be used in this loop:
- Fidelity filters check whether the generated output preserves the meaning of the input.
- Length filters control compression and prevent overly long outputs.
- Contextual filters check whether the output remains coherent in the broader context.
- Consistency filters check whether generated statements contradict each other.
- Quality filters remove vague, irrelevant, or low-confidence outputs.
This approach is useful when the goal is to create high-quality training data without relying on a large manually annotated dataset. The large model provides the initial knowledge, and the student gradually learns to produce more compact and controlled outputs.
The main benefit is scalability. A strong teacher can bootstrap a smaller student, and the student can eventually generate useful data more cheaply than the original teacher.
Distillation Using Reinforcement Learning
Another approach uses reinforcement learning ideas to improve the distillation process. Here, the model generates multiple candidate outputs, and a reward model or scoring function ranks them. Higher-quality outputs are selected for further training.
The process usually has two stages:
- Generate candidate responses from the current model policy.
- Filter or rank those responses using a reward model, critic, or human preference signal.
The language model is then fine-tuned on the selected outputs, often using an offline reinforcement learning objective or preference-aligned training method. Over time, the model learns to generate outputs that are more likely to pass the quality filter.
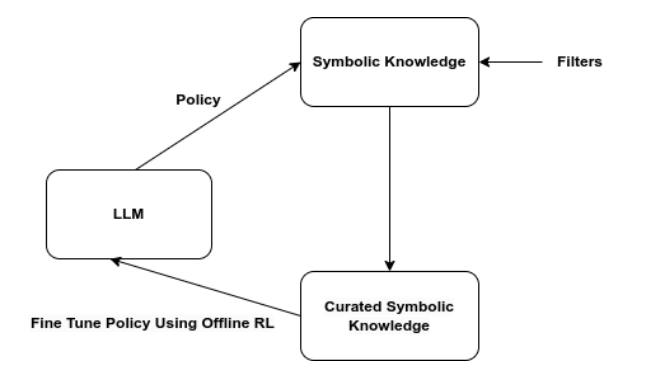
This approach is especially useful when there is no single perfect answer but there are clear preferences. For example, we may prefer explanations that are faithful, concise, harmless, factually grounded, and easy to understand. A reward model can help select outputs that match those preferences.
Reinforcement learning-based distillation has been used in areas such as commonsense reasoning, summarization, translation, mathematical reasoning, and preference alignment.
What Makes the Knowledge “Symbolic”?
The word symbolic can mean different things depending on the system. In this context, symbolic knowledge generally means knowledge represented in a form that has explicit structure and can be manipulated.
Examples include:
- Logic rules.
- If-then rules.
- Knowledge graph triples.
- Ontologies.
- Semantic frames.
- Tables.
- Programs.
- Decision rules.
- Structured explanations.
This is different from hidden neural activations. A hidden vector may encode useful information, but it is not directly readable. A symbolic rule or graph edge can be inspected and corrected.
That inspectability is the main advantage. Symbolic knowledge can support reasoning, auditing, debugging, compliance, and human trust.
Why LLMs Are Good Teachers
LLMs are useful teachers because they have absorbed broad patterns from language, code, and structured text. They can generate examples, explain concepts, propose rules, compare cases, and translate between formats.
For symbolic distillation, this means an LLM can help create knowledge artifacts that would otherwise require a large amount of manual effort.
But LLMs are imperfect teachers. They can hallucinate, overgeneralize, produce inconsistent rules, or generate confident statements without evidence. That is why symbolic distillation should be paired with verification, retrieval, expert review, and benchmark testing.
The goal is not to blindly trust the teacher. The goal is to use the teacher as a powerful generator, then filter and structure its outputs carefully.
Applications
Symbolic knowledge distillation can support several practical applications.
In explainable AI, distilled rules or rationales can make model behavior easier to inspect. In healthcare or finance, symbolic outputs can help support compliance and expert review. In education, LLM-generated structured examples can train smaller tutoring systems. In commonsense reasoning, distilled knowledge graphs can give models explicit background knowledge. In enterprise settings, symbolic distillation can turn a large model’s output into domain-specific rules or workflows.
It is also useful for smaller model training. A compact student model trained on high-quality distilled symbolic data may perform well in a narrow domain while being cheaper and easier to deploy than the original LLM.
Challenges
Symbolic distillation is promising, but it is difficult.
The first challenge is correctness. A symbolic representation looks authoritative, so errors can become more dangerous if they are stored as rules or facts.
The second challenge is coverage. A knowledge base may be accurate but incomplete. Missing rules can cause failures when the system faces a new case.
The third challenge is representation. The same knowledge can be written as text, logic, a graph, a table, or a program. Choosing the right format depends on the downstream task.
The fourth challenge is evaluation. We need ways to test not only whether a small model performs well, but whether the distilled symbolic knowledge is faithful, useful, and safe.
Final Thoughts
Symbolic knowledge distillation is a natural next step for large language models. As LLMs become more powerful, we need better ways to extract what they know, check it, and reuse it in smaller and more transparent systems.
Traditional distillation makes models more efficient. Symbolic distillation can also make knowledge more explicit. That combination matters for the future of neurosymbolic AI, explainable AI, and trustworthy AI.
The key lesson is simple: the value of a large model is not only in running it directly. Some of its value can be distilled into knowledge that people and smaller systems can inspect, improve, and deploy.
References
- Acharya, K., Velasquez, A. and Song, H.H., 2024. A Survey on Symbolic Knowledge Distillation of Large Language Models. IEEE Transactions on Artificial Intelligence, 5(12), pp. 5928-5948. https://doi.org/10.1109/TAI.2024.3428519
- arXiv version. https://arxiv.org/abs/2408.10210