The history of large language models is also the history of a tension: models keep getting more capable as they grow, but growth makes them harder to train, deploy, inspect, and trust.
Knowledge distillation enters that story as a practical response. If a large model contains valuable knowledge, can we transfer some of it into a smaller, cheaper, and more understandable form? That question has become more urgent as language models have moved from early statistical systems to billion- and trillion-parameter architectures.
This timeline follows the major milestones that shaped language modeling and knowledge distillation, with special attention to why symbolic knowledge distillation has become an important direction for the next generation of AI systems.
A Long Road to Language Intelligence
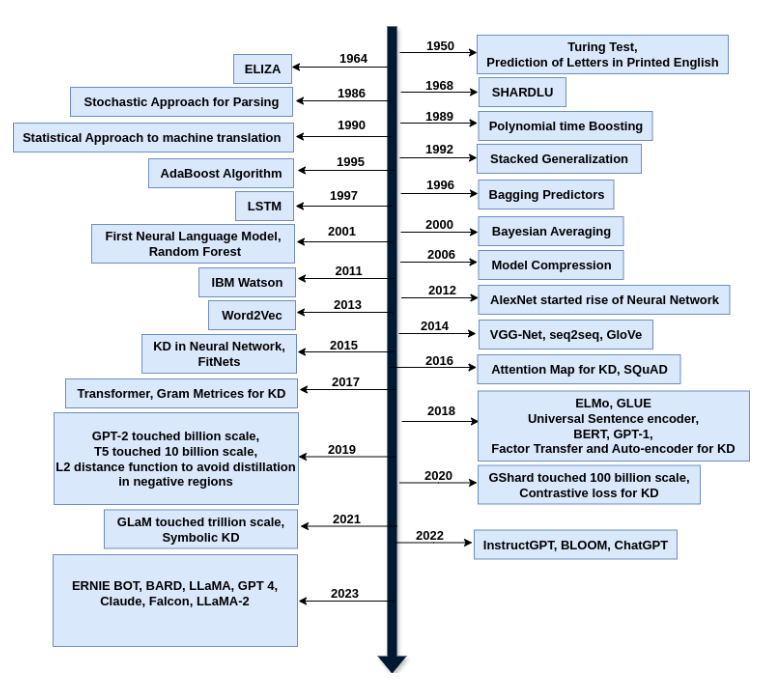
The journey begins long before transformers. In 1950, Alan Turing’s famous question about whether machines can think helped define the ambition of artificial intelligence. Around the same period, Claude Shannon’s work on information theory gave researchers a mathematical way to think about prediction, uncertainty, and sequences of symbols.
Early systems like ELIZA in the 1960s showed that computers could mimic conversation, even if the underlying understanding was shallow. SHRDLU, introduced later in the decade, demonstrated a more structured form of language understanding inside a simplified block world. These systems were limited, but they established two ideas that still matter: language is interactive, and meaning depends on context.
Statistical Language Models
For many years, natural language processing was dominated by statistical methods. Researchers used probabilities, n-grams, hidden Markov models, and statistical parsing to model language from observed data.
Statistical language models were useful because they moved NLP away from hand-written rules alone. Instead of telling the machine every rule of grammar and meaning, researchers could estimate patterns from corpora.
But these models had limits. They often made simplifying independence assumptions, struggled across domains, and had difficulty representing long-range meaning. They could count patterns, but they did not deeply understand language.
Neural Language Models
The neural era changed the direction of the field. Long Short-Term Memory networks, introduced in 1997, helped sequence models capture longer dependencies and reduce the vanishing-gradient problem. In the early 2000s, neural language models began showing that distributed representations could learn richer patterns than traditional statistical approaches.
This period mattered because language moved from sparse counts to dense vectors. Words, phrases, and eventually sentences could be represented in continuous spaces where similarity and meaning were encoded geometrically.
Word2Vec in 2013 made this idea widely influential by showing that word relationships could be captured through efficient vector representations. GloVe followed with another influential embedding approach based on global co-occurrence statistics.
Sequence-to-Sequence Models and Attention
In 2014, sequence-to-sequence models gave neural networks a powerful framework for translation and other text generation tasks. An encoder compressed the input sequence into a representation, and a decoder generated the output sequence.
Attention mechanisms then improved this setup by letting the decoder focus on different parts of the input instead of relying on one fixed vector. This was a major step toward modern language models because it allowed models to handle longer and more complex dependencies.
Around the same time, knowledge distillation was formalized as a practical compression method. Hinton, Vinyals, and Dean’s 2015 paper showed how a smaller model could learn from the softened outputs of a larger teacher model or ensemble.
The Rise of Knowledge Distillation
Knowledge distillation began as a way to compress large models. Instead of deploying an expensive ensemble, we could train a student model to imitate the teacher’s behavior.
The teacher’s soft probabilities contain more information than hard labels. For example, if the correct answer is “cat,” the teacher may still show that “fox” and “dog” are more plausible than “airplane.” That extra structure helps the student learn better decision boundaries.
Over time, distillation expanded beyond output probabilities. Researchers developed feature-based methods, relation-based methods, attention transfer, FitNets, contrastive losses, dataset distillation, and many task-specific variants. Distillation became useful not only for compression, but also for transfer learning, privacy, robustness, continual learning, and model adaptation.
Transformers Change the Scaling Curve
The 2017 Transformer paper, “Attention Is All You Need,” changed the field dramatically. By replacing recurrence with self-attention, transformers made it easier to train models in parallel and capture long-range dependencies.
This architecture became the foundation for BERT, GPT, T5, and many later large language models. BERT showed the power of bidirectional pretraining for language understanding. GPT-style models showed how autoregressive pretraining could produce increasingly capable text generators.
The key shift was pretraining. Instead of training a separate model from scratch for every task, researchers trained large models on broad text corpora and then adapted them to downstream tasks through fine-tuning, prompting, or instruction tuning.
Benchmarks and Pretrained Language Models
By 2018, benchmarks such as GLUE helped standardize evaluation for language understanding. Models like ELMo, BERT, and GPT-1 showed that pretrained representations could improve many NLP tasks.
This was the beginning of the modern pretrained language model era. Model size, data scale, and compute became central drivers of progress. The field increasingly learned that general-purpose pretraining could produce reusable capabilities.
But this also increased the need for distillation. Large pretrained models were powerful, but they were expensive to deploy. Smaller models like DistilBERT and TinyBERT showed that distillation could make transformer-based systems more practical.
From Billions to Trillions of Parameters
In 2019 and 2020, model scale accelerated. GPT-2 reached the billion-parameter range, and GPT-3 reached 175 billion parameters. GPT-3’s few-shot behavior made clear that scale could produce new capabilities, including task adaptation from examples in a prompt.
Other models, including T5, GShard, and GLaM, continued this scaling trend. Mixture-of-experts architectures showed that models could reach very large parameter counts while activating only part of the network for each input.
Scaling laws helped explain why this worked: performance often improved predictably as model size, data, and compute increased. But they also made the cost problem impossible to ignore. Larger models require more data, more hardware, more energy, and more specialized deployment infrastructure.
Why Distillation Became More Important
As LLMs grew, distillation became less optional. Organizations wanted the capability of large models without always paying the full inference cost. They also needed models that could run in lower-resource environments, protect data, respond quickly, and be easier to control.
Distillation helped in several ways:
- Compressing large models into smaller students.
- Training task-specific models from general-purpose teachers.
- Generating synthetic data for smaller models.
- Transferring reasoning patterns, explanations, or preferences.
- Reducing deployment cost while preserving useful capability.
The field also began to recognize that not all knowledge should remain hidden in weights. Some knowledge needs to be inspected, corrected, reused, and connected to explicit reasoning systems.
Symbolic Knowledge Distillation
Symbolic knowledge distillation extends the teacher-student idea beyond logits and hidden states. Instead of only transferring numerical behavior, it tries to extract knowledge into symbolic forms such as rules, structured datasets, knowledge graphs, logic statements, rationales, programs, or concept representations.
This is especially relevant for LLMs. Large language models contain broad implicit knowledge, but that knowledge is difficult to audit. Symbolic distillation tries to turn parts of that implicit knowledge into explicit artifacts that humans and smaller systems can inspect.
For example, an LLM might generate explanations, factual triples, decision rules, or reasoning traces. Those outputs can be filtered, validated, structured, and used to train smaller models or support neuro-symbolic reasoning.
The goal is not only efficiency. It is also interpretability, transparency, and trust.
The Data and Compute Pressure
Recent research also raises a practical concern: high-quality training data is not infinite. If model performance depends only on scaling model size and data, progress may eventually hit limits from data availability, cost, copyright, quality, and compute constraints.
This makes distillation more important. Instead of relying only on more raw data, future systems may need to reuse knowledge more efficiently. Teacher models may generate curated training data. Smaller models may specialize in tasks. Symbolic representations may help preserve important knowledge in forms that are easier to inspect and reuse.
What Comes Next
The next phase of language models is likely to combine several ideas: larger teacher models, smaller deployable students, synthetic data generation, self-improvement, retrieval, symbolic reasoning, tool use, verification, and human feedback.
Knowledge distillation will remain central because it helps bridge research-scale models and practical AI systems. Symbolic knowledge distillation adds another layer by asking whether we can make the distilled knowledge more explicit and trustworthy.
The milestone story is not just about bigger models. It is about learning how to preserve, compress, explain, and reuse what those models know.
Final Thoughts
Language models have evolved from early rule-based and statistical systems to transformers and massive pretrained models. Along the way, knowledge distillation grew from a model-compression trick into a broad strategy for transferring capability.
As LLMs become more powerful, the need for efficient and interpretable students becomes stronger. Symbolic knowledge distillation is one promising response: it aims to turn hidden model knowledge into forms that are more structured, inspectable, and useful.
The future of AI will not be only about building the largest model. It will also be about distilling the right knowledge into systems that people can afford, deploy, understand, and trust.
References
- Acharya, K., Velasquez, A. and Song, H.H., 2024. A Survey on Symbolic Knowledge Distillation of Large Language Models. IEEE Transactions on Artificial Intelligence, 5(12), pp. 5928-5948. https://doi.org/10.1109/TAI.2024.3428519
- Hinton, G., Vinyals, O. and Dean, J., 2015. Distilling the Knowledge in a Neural Network. arXiv:1503.02531. https://arxiv.org/abs/1503.02531
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L. and Polosukhin, I., 2017. Attention Is All You Need. arXiv:1706.03762. https://arxiv.org/abs/1706.03762
- Brown, T.B. et al., 2020. Language Models are Few-Shot Learners. arXiv:2005.14165. https://arxiv.org/abs/2005.14165