Modern machine learning models can be extremely powerful, but that power often comes with a cost. Large models are expensive to train, slow to run, hard to deploy on small devices, and sometimes too opaque for sensitive applications.
Knowledge distillation is one way to reduce that cost. The idea is simple: train a smaller student model to learn from a larger teacher model. If the process works well, the student becomes faster and lighter while preserving much of the teacher’s performance.
This is especially useful when a large model performs well in research but is too heavy for real deployment. A model running on a phone, browser, robot, vehicle, medical device, or edge server may need to be compact, efficient, and reliable. Distillation helps move intelligence from a large system into a smaller one.
The Teacher-Student Idea
In standard supervised learning, a model learns from ground-truth labels. If the image is a cat, the label says “cat.” If the sentence is positive, the label says “positive.”
In knowledge distillation, the student also learns from the teacher’s behavior. The teacher may provide class probabilities, intermediate features, attention maps, relationships between examples, generated rationales, rules, or other forms of guidance.
This matters because the teacher often knows more than the hard label. For example, an image may be labeled “dog,” but the teacher’s probabilities might show that the image also looks somewhat like a wolf or fox. Those softer signals carry useful information about class similarity.
Why Distillation Works
Knowledge distillation works because trained models contain structure learned from data. A good teacher does not merely memorize labels; it learns patterns, representations, boundaries, and relationships.
The student benefits from this richer signal. Instead of learning only from a one-hot label, it learns how the teacher distributes belief, how the teacher represents intermediate concepts, or how the teacher relates examples to one another.
The result is often a smaller model that trains more smoothly and performs better than a similarly sized model trained only on hard labels.
Traditional Knowledge Distillation
Traditional knowledge distillation is usually grouped into three major types: response-based, feature-based, and relation-based.
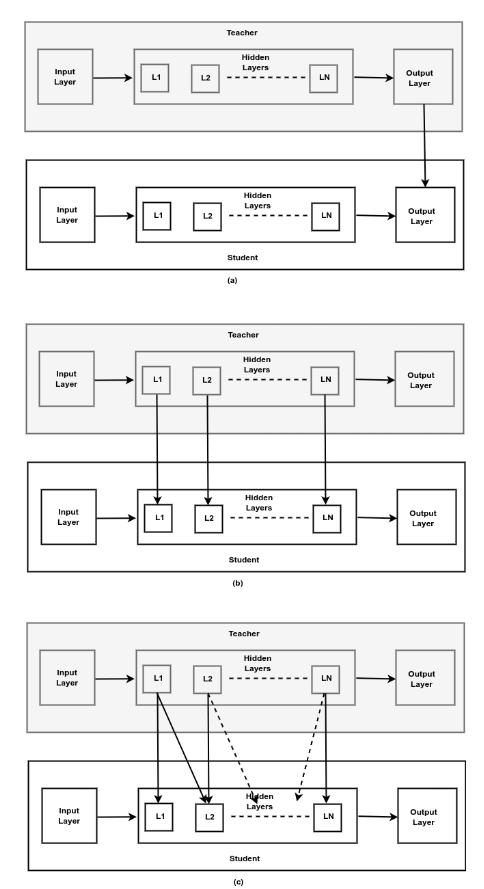
Each type answers a different question:
- What does the teacher predict?
- How does the teacher internally represent the input?
- What relationships has the teacher learned between layers, examples, or classes?
Response-Based Knowledge Distillation
Response-based distillation transfers knowledge from the teacher’s final output. In classification, this usually means the student learns from the teacher’s logits or probability distribution.
The classic example is soft-target distillation. Instead of training the student only on hard labels, we train it to match the teacher’s softened probability distribution. A temperature parameter is used to make the probability distribution less sharp, revealing more information about secondary classes.
For example, if the correct class is “truck,” a hard label gives the student only one target. A teacher might reveal that the example is also somewhat similar to “bus” and less similar to “bicycle.” That extra structure can help the student learn better decision boundaries.
Response-based distillation is popular because it is simple, model-agnostic, and easy to implement. It is commonly used in classification, object detection, speech recognition, and natural language processing.
Its limitation is that it uses only the final output. Deep models learn rich internal representations, and response-based distillation may ignore much of that hidden knowledge.
Feature-Based Knowledge Distillation
Feature-based distillation transfers knowledge from intermediate layers. Instead of only matching the teacher’s final answer, the student tries to match selected internal representations.
This can be especially helpful when the student is small but still needs to learn high-quality features. FitNets popularized this idea by training a thinner student network to imitate hidden-layer activations from a larger teacher.
Feature-based methods can use attention maps, activation boundaries, hidden states, or other intermediate signals. In computer vision, this may mean matching spatial feature maps. In language models, it may mean matching hidden states or attention patterns.
The advantage is that the student receives richer guidance. The teacher shows not only the answer but part of the reasoning path encoded in its representation.
The challenge is alignment. Teacher and student models may have different depths, widths, architectures, and hidden dimensions. Choosing which layers to match and how to transform them is not always obvious.
Relation-Based Knowledge Distillation
Relation-based distillation focuses on relationships rather than individual outputs or features.
The relationship may be between examples, between layers, between feature maps, or between multiple teacher models. For instance, a student may learn that two images are close in the teacher’s representation space, or that two feature maps interact in a particular way.
This type of distillation can capture structure that is not visible from one prediction at a time. Methods such as Flow of Solution Process use relationships between feature maps, while other approaches use pairwise distances, graph structures, similarity matrices, or attention-based relations.
Relation-based distillation is powerful because it teaches the student how the teacher organizes information. Instead of copying one answer, the student learns part of the teacher’s geometry of knowledge.
The difficulty is complexity. Relational knowledge can be expensive to compute, hard to select, and sensitive to how similarity is defined.
Symbolic Knowledge Distillation
Traditional distillation usually transfers numerical behavior: logits, features, attention, or relationships. Symbolic knowledge distillation takes a different direction. It tries to extract knowledge from a model into explicit symbolic forms such as rules, logic statements, structured datasets, knowledge graphs, programs, rationales, or concept-level representations.

This is especially relevant for large language models. LLMs contain large amounts of implicit knowledge, but that knowledge is buried inside model weights and expressed through generated text. Symbolic distillation aims to make some of that knowledge more inspectable, reusable, and controllable.
For example, a large teacher model may generate reasoning traces, rules, question-answer pairs, explanations, or structured facts. Those outputs can be filtered, converted into a dataset or knowledge base, and used to train smaller models or support symbolic reasoning systems.
The goal is not only compression. Symbolic distillation can also improve interpretability. A rule or knowledge graph is easier to inspect than a vector of hidden activations. This makes symbolic distillation attractive for high-stakes domains where transparency matters.
Traditional vs. Symbolic Distillation
Traditional distillation usually asks the student to imitate the teacher’s behavior. Symbolic distillation asks the system to extract and represent the teacher’s knowledge in a more explicit form.
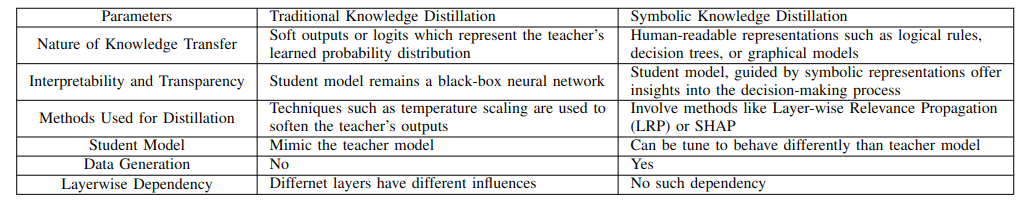
The difference is important:
- Traditional KD is often optimized for performance and efficiency.
- Symbolic KD is often optimized for interpretability, structure, and reuse.
- Traditional KD usually produces a smaller neural model.
- Symbolic KD may produce rules, graphs, datasets, explanations, or hybrid neuro-symbolic systems.
In practice, the two can be combined. A symbolic distillation pipeline may use an LLM to generate structured training data, then train a smaller neural model on that data. A traditional student model may also be supported by symbolic constraints or explanations.
When to Use Each Type
Response-based distillation is a strong default when you want a simple compression pipeline. It is easy to implement and works well when the teacher’s final predictions contain enough useful information.
Feature-based distillation is useful when representation quality matters, especially in deep vision or language models. It can help smaller students learn better intermediate abstractions.
Relation-based distillation is useful when the structure among examples, layers, or classes matters. It is often more complex but can transfer deeper organization from the teacher.
Symbolic distillation is useful when interpretability, reasoning, explicit knowledge, or high-stakes trust matters. It is particularly promising for LLMs, neurosymbolic AI, knowledge graphs, rule extraction, and explainable AI.
Limitations
Knowledge distillation is not magic. A student model has limited capacity, so it may not fully reproduce the teacher. A poor teacher can transfer poor behavior. Distilled models may also inherit bias, hallucination patterns, or brittle reasoning from the teacher.
Distillation also depends on the quality of the transfer signal. Badly chosen layers, noisy generated data, weak symbolic extraction, or incorrect temperature settings can reduce performance.
For symbolic distillation, validation is especially important. Extracted rules or structured facts should be checked for correctness, consistency, and coverage before being used in downstream systems.
Final Thoughts
Knowledge distillation is one of the most practical ideas in modern AI because it connects performance with deployability. It helps move knowledge from large, expensive models into smaller systems that can run faster and cheaper.
The field has also expanded beyond compression. Response-based, feature-based, and relation-based methods focus on transferring neural behavior. Symbolic knowledge distillation goes further by trying to make hidden model knowledge explicit, interpretable, and reusable.
As AI systems become larger and more expensive, distillation will remain important. The future is not only about building bigger teachers. It is also about learning how to extract their knowledge into systems that are efficient, trustworthy, and easier to understand.
References
- Acharya, K., Velasquez, A. and Song, H.H., 2024. A Survey on Symbolic Knowledge Distillation of Large Language Models. IEEE Transactions on Artificial Intelligence, 5(12), pp. 5928-5948. https://doi.org/10.1109/TAI.2024.3428519
- Hinton, G., Vinyals, O. and Dean, J., 2015. Distilling the Knowledge in a Neural Network. arXiv:1503.02531. https://arxiv.org/abs/1503.02531
- Gou, J., Yu, B., Maybank, S.J. and Tao, D., 2021. Knowledge Distillation: A Survey. International Journal of Computer Vision, 129, pp. 1789-1819. https://doi.org/10.1007/s11263-021-01453-z