Fire departments do not have unlimited inspection capacity. They have to decide which buildings to inspect first, often across tens of thousands of properties, while fire incidents remain rare and difficult to predict.
Traditionally, those decisions rely on experience, intuition, complaint history, age of the building, or simple rule-based criteria. Those signals are useful, but they do not fully capture the many factors that shape fire risk. A property’s occupancy type, construction material, inspection history, code violations, location, utility disconnections, and prior incidents may all matter together.
Dey and Fern’s AAAI 2024 paper studies how machine learning can help. Their goal is not to replace fire inspectors. It is to give departments a data-driven ranking of city properties so limited inspection resources can be directed toward higher-risk buildings.
The Core Problem
The task is best understood as a ranking problem. Given a list of city properties, the model estimates the probability that each property will experience a structural fire. Those probabilities can then be used to rank properties from highest to lowest risk.
This framing is practical. A fire department may not need a perfect yes-or-no prediction for every building. It needs to know which properties should rise to the top of the inspection list.
That is also why the evaluation focuses on ranking quality. If the model’s top-ranked properties contain a larger share of future fire incidents than a random ranking, the model can help inspectors use their time more effectively.
The Dataset
The study uses data from a South Dakota fire department, covering more than 72,000 city properties. The raw data combines multiple sources, joined primarily through address and location information.
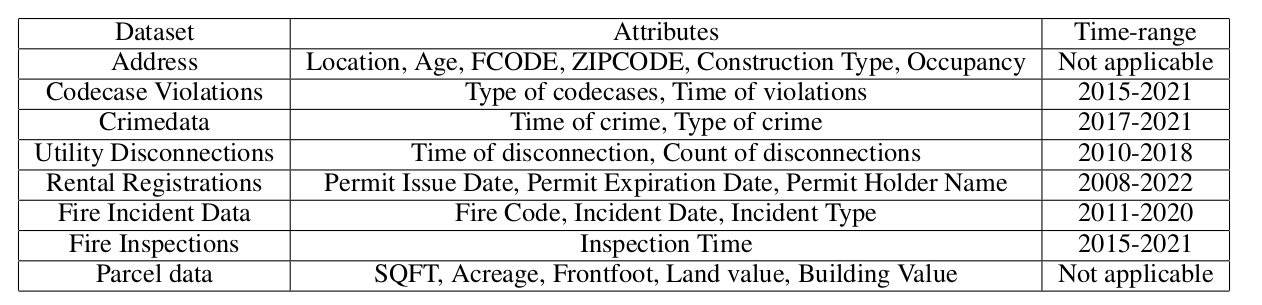
The data includes property characteristics such as age, construction type, occupancy type, square footage, and location. It also includes historical fire incidents, fire inspections, code violations, crime counts, and utility disconnections.
The paper focuses specifically on structural fires, identified by fire code 111. This keeps the prediction task focused on building-related fire risk rather than mixing in other fire types.
One of the biggest challenges is class imbalance. Only about 1.3% of properties in the dataset experienced a fire incident. That means a naive model could look accurate by predicting “no fire” almost everywhere, while being useless for inspection prioritization.
Feature Engineering
The authors convert raw city records into a feature set that a machine learning model can use.
Some features are time-invariant, such as construction type or occupancy type. Others change over time, such as inspections, code violations, and utility disconnections. The time-varying features are aggregated across the 2011-2021 period, usually as counts. For example, the model may use the number of inspections or the number of code violations associated with a property.
The authors also encode location using geohashes generated from latitude and longitude. This gives the model a way to learn neighborhood-level risk patterns without manually defining districts.
The final dataset includes 24 primary features: 14 numeric and 10 categorical. After one-hot encoding categorical variables, the feature space expands to 698 features.
Why XGBoost Fits the Problem
The paper evaluates several models, including XGBoost, AdaBoost, and Random Forest. XGBoost is especially attractive for this application because it handles missing values and imbalanced classes well.
Missing data is common in city records. Some properties may lack certain inspection details, construction attributes, or utility information. Instead of discarding large parts of the dataset, XGBoost can learn useful decision paths even when some values are absent.
The model also supports weighting the positive class, which matters because fire incidents are rare. The authors tune the positive class weight through five-fold cross-validation.
The dataset is split into 75% training and 25% testing while preserving the original class imbalance. In the test set, 320 properties experienced fire incidents out of 23,947 properties.
How the Model Is Evaluated
Accuracy is not the right metric for this problem. Because fires are rare, a model could predict “no fire” for almost every property and still achieve high accuracy.
Instead, the paper uses ranking metrics, including Area Under the Curve (AUC), and cumulative fire count curves. AUC measures whether properties that experienced fires tend to receive higher risk scores than properties that did not.
The cumulative fire count curve is especially intuitive. If the fire department inspected properties in the model’s ranked order, how many actual fire incidents would appear near the top of the list? A good model should concentrate more fire-positive properties early in the ranking.
Results
In the full dataset experiments, XGBoost performs strongly. The model achieves an AUC of 0.757 on the test set and significantly outperforms random ranking.
That result is meaningful because the task is difficult. Structural fires are rare, city data is incomplete, and risk depends on many interacting factors.
The authors also run reduced-dataset experiments where properties with missing values are removed. In that setting, Random Forest performs best with an AUC of 0.699. However, the reduced dataset performs worse overall than the full dataset, which reinforces the value of using models that can handle missing data instead of throwing away incomplete records.
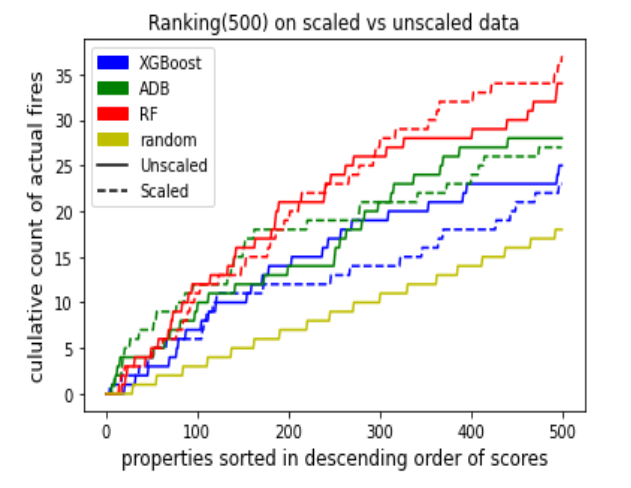
The main takeaway is not that one model is universally best. It is that a data-driven ranking can outperform random or simple prioritization, and that preserving incomplete but useful city records can improve performance.
Feature Importance
The authors also analyze feature importance to better understand what the model is using.
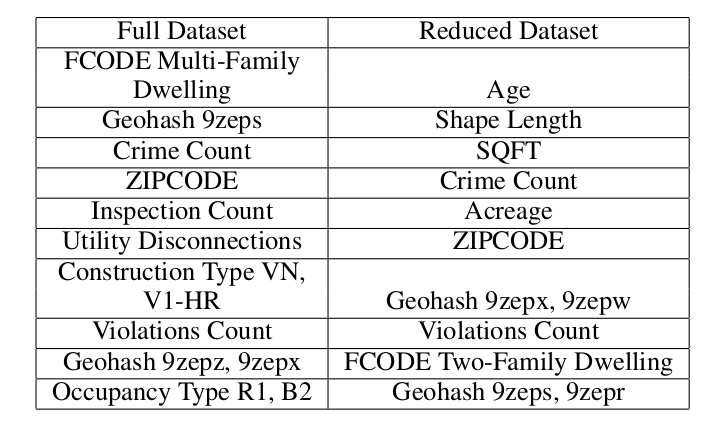
Important features include property type, location, zip code, inspection count, utility disconnections, construction type, code violations, occupancy type, and crime count.
Many of these make intuitive sense. Utility disconnections may signal property neglect or electrical and gas-related risk. Fire code violations directly indicate safety problems. Wood-framed construction types are more combustible. Occupancy type matters because residential, business, and multi-family buildings have different hazards and usage patterns.
Feature importance is not the same as causation, but it helps build trust. If the model’s important features align with domain intuition, fire departments may be more willing to test the system in practice.
Why This Matters for Fire Departments
The value of this work is operational. Fire departments need to decide where to spend inspection time. A good risk ranking can help them:
- Prioritize inspections more consistently.
- Identify properties that may not be obvious from intuition alone.
- Use limited staff time more effectively.
- Support prevention instead of only response.
- Build a repeatable process that can be updated as new data arrives.
This kind of model does not need to make final decisions. It can serve as a decision-support tool that inspectors review alongside local knowledge.
Limitations
The dataset comes from one city in South Dakota, so the model should not be assumed to generalize directly to every city. Building stock, climate, occupancy patterns, code enforcement, utility practices, socioeconomic conditions, and fire department records differ by region.
The paper also notes that the data is not public, which makes direct comparison with other methods difficult. This is a common challenge in public-safety AI because sensitive municipal datasets are rarely open.
Another limitation is that feature importance does not explain every individual prediction. A fire department using this system may need more interpretable interfaces so inspectors can understand why a property appears high on the list.
Final Thoughts
Fire prevention is a strong use case for practical machine learning because the goal is not abstract prediction. The goal is better allocation of scarce inspection resources.
Dey and Fern show that historical property, inspection, violation, incident, and location data can be turned into useful fire-risk rankings. XGBoost performs well because it can work with missing values and rare positive cases, both of which are common in city safety data.
The larger message is simple: data-driven risk prediction can help public agencies act earlier. If a model helps inspectors find high-risk properties before a fire occurs, it can support safer buildings, better prevention, and more efficient public service.
References
- Dey, R. and Fern, A., 2024. Data-Driven Structural Fire Risk Prediction for City Properties. Proceedings of the AAAI Conference on Artificial Intelligence, 38(21), pp. 22885-22891. https://doi.org/10.1609/aaai.v38i21.30325
- AAAI proceedings record. https://ojs.aaai.org/index.php/AAAI/article/view/30325