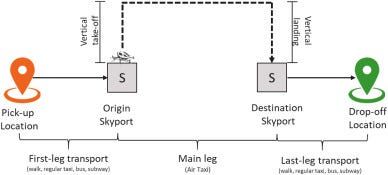
Air taxi planning is not only about designing aircraft or building vertiports. It also depends on a question operators will have to answer every hour: where will demand appear next?
If demand is underestimated, passengers wait too long and aircraft sit in the wrong places. If demand is overestimated, operators waste fleet capacity, staffing, and infrastructure. A successful urban air mobility network needs to understand not just total demand, but demand by location, hour, day, season, and weather condition.
Rajendran, Srinivas, and Grimshaw approach this problem as a machine learning classification task. Instead of predicting an exact passenger count, the study predicts whether air taxi demand in a given place and time will be low, moderate, or high. That framing is useful for operations because many real decisions are also categorical: send more vehicles, hold capacity steady, or reduce service.
What the Study Tries to Predict
The paper focuses on potential air taxi demand in New York City. Since large commercial air taxi services were not yet available, the researchers build on estimated demand from earlier work using NYC taxi trip data. A ground taxi ride becomes a candidate air taxi trip only when it satisfies practical operating assumptions: the request is on demand, the passenger uses no more than one VTOL flight leg, and the air taxi trip saves at least 40% of the travel time compared with ground transportation.
That estimated demand is then converted into a supervised learning problem. For each location and time period, the model learns whether demand should be classified as low, moderate, or high.
This is a sensible way to think about early air taxi operations. A company may not need perfect passenger counts to make a first decision. It needs to know which stations are likely to heat up during Monday morning, which areas slow down on weekends, and how weather or visibility might affect demand.
Preparing the Data
The estimated air taxi records include pickup and drop-off date and time, passenger count, origin latitude and longitude, and destination latitude and longitude. Those raw fields are useful, but they are not yet in the best shape for machine learning.
The first step is to turn pickup coordinates into service regions. The authors use k-means clustering to partition pickup locations into different geographic areas, also referred to as location IDs. This gives the model a cleaner way to learn spatial patterns without treating every coordinate as a completely separate place.
Next, the pickup timestamp is transformed into temporal features such as month, day of week, hour of day, and weekday or weekend indicator. The data is then grouped by location ID, date, and hour. This produces the kind of structured demand table a model can learn from: where the demand happened, when it happened, and what conditions surrounded it.

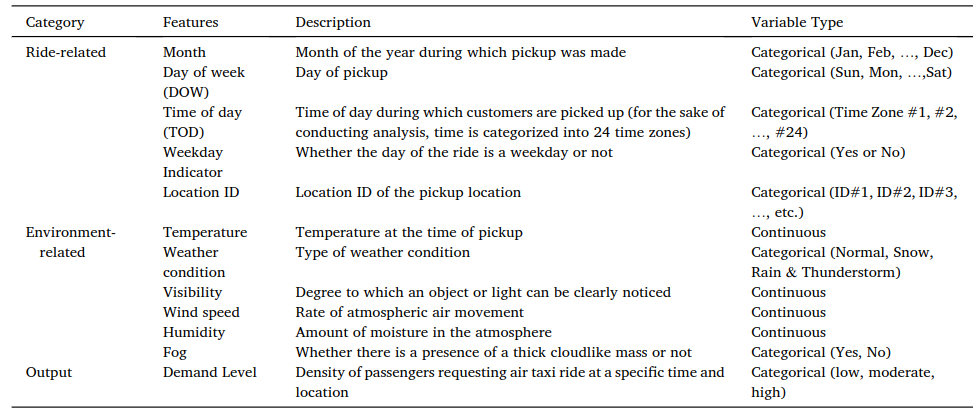
The study also includes weather-related predictors such as temperature, weather condition, precipitation, and visibility. This matters because air taxi demand is not purely a transportation pattern. Bad weather can change rider behavior, affect aircraft operations, and alter the reliability of the service.
Like most real mobility datasets, the data contains missing or inconsistent values. The authors consider two broad strategies. One is imputation, where missing or incorrect values are replaced using methods such as median, mode, or regression-based estimates. The other is listwise deletion, where incomplete rows are removed. These decisions are not glamorous, but they can strongly affect model performance because machine learning systems learn exactly what the prepared dataset allows them to learn.
The Four Machine Learning Models
The paper compares four popular machine learning algorithms: multinomial logistic regression, artificial neural networks, random forests, and gradient boosting.
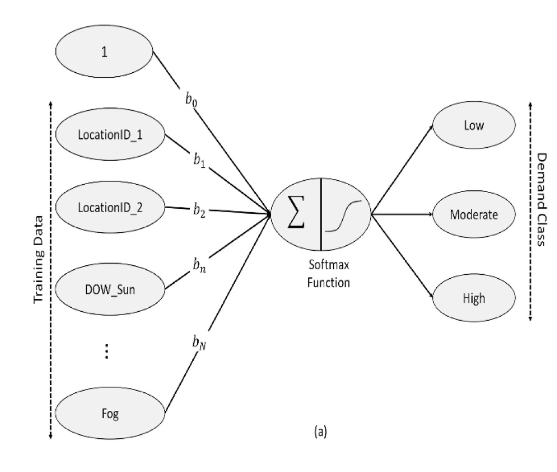
Multinomial Logistic Regression
Multinomial logistic regression is the most interpretable baseline. It estimates the probability that a demand observation belongs to one of several categories: low, moderate, or high. It is useful because it provides a clear benchmark and helps reveal whether simpler linear relationships already explain much of the demand pattern.
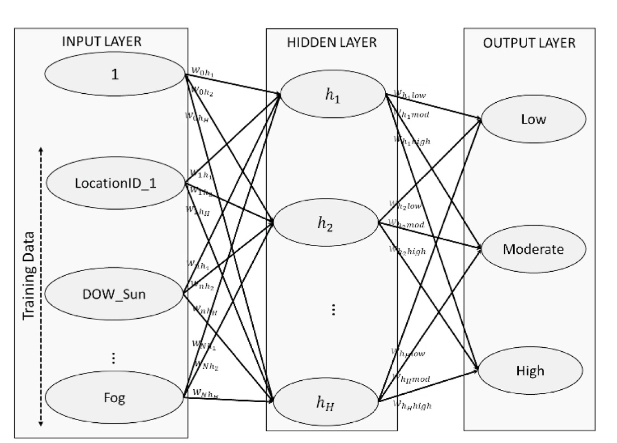
Artificial Neural Network
The neural network model is designed to capture more complex relationships between the predictors and demand level. For example, the effect of hour of day may depend on location, and the effect of weather may differ between airport trips and central-city trips. Neural networks can represent these nonlinear patterns, although they are usually less transparent than simpler models.
Random Forests
Random forests combine many decision trees and average their predictions. This makes them strong general-purpose models for tabular data because they can handle nonlinear relationships, interactions between variables, and mixed feature types. They are also less dependent on a single unstable tree.
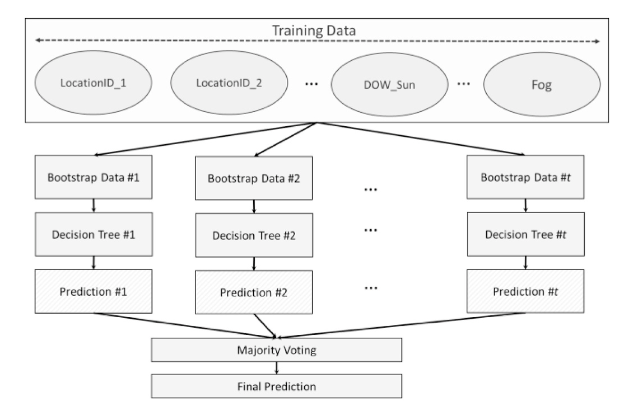
Gradient Boosting
Gradient boosting also uses decision trees, but it builds them sequentially. Each new tree focuses on correcting the errors made by the previous ones. This often makes gradient boosting especially powerful for structured prediction problems where many small signals combine to shape the final outcome.
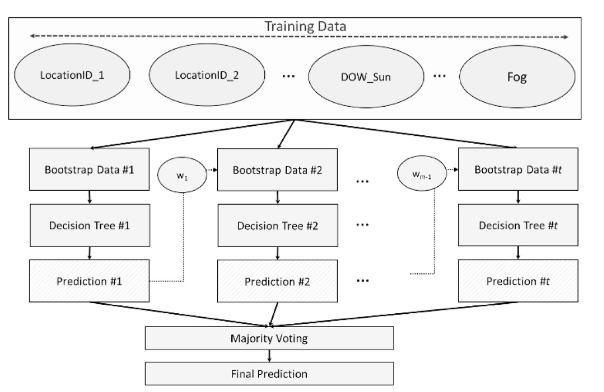
What the Results Show
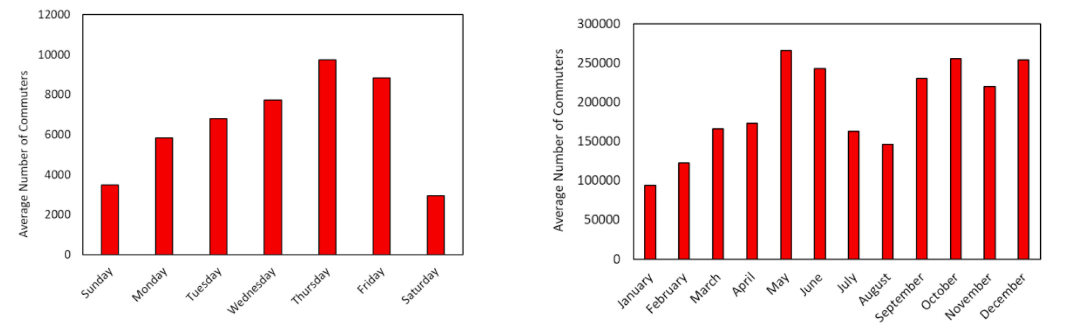
The results show that air taxi demand is strongly shaped by time and place. Certain locations, time periods, and weekdays repeatedly emerge as important predictors. That is exactly what operators should expect in a city like New York: airport flows, work trips, nightlife, tourism, and weekday commuting all create different demand rhythms.
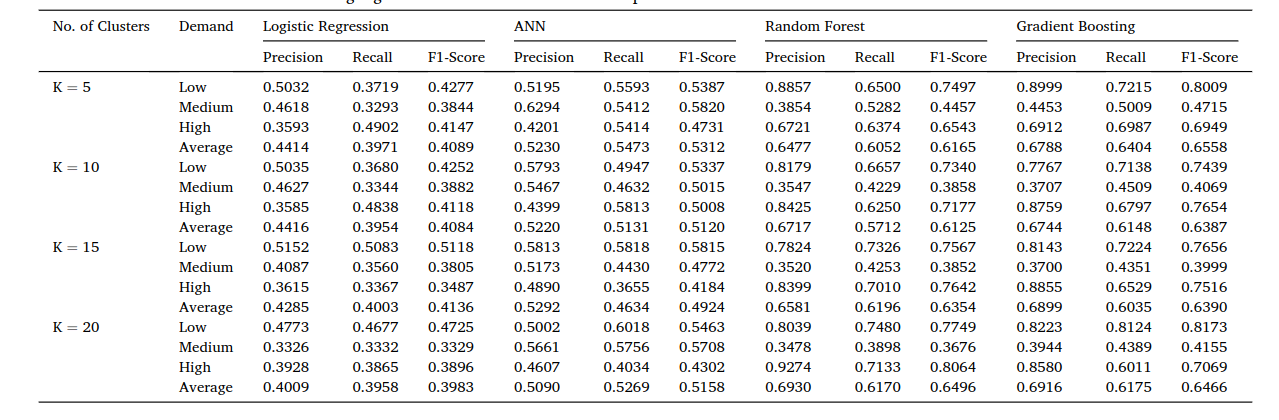
Among the four models, gradient boosting delivers the strongest predictive performance in the study. That result is not surprising. Demand is rarely driven by one clean variable. It is shaped by combinations: a specific station, at a specific hour, on a specific weekday, under a specific weather condition. Gradient boosting is well suited for learning those layered patterns from tabular data.

The feature importance analysis is especially useful. It shows that location, time period, and weekday patterns are not just background information; they are central signals for predicting demand level. For an air taxi company, these features can guide decisions about vehicle positioning, staffing, charging schedules, dispatch planning, and infrastructure utilization.
Why This Matters for Urban Air Mobility
Air taxi networks will be expensive to operate. Aircraft, pilots or autonomy systems, batteries, charging infrastructure, vertiports, maintenance, insurance, and regulatory compliance all create high fixed and operational costs. That means demand forecasting is not optional. It is part of the business model.
A model like this can help operators answer practical questions:
- Which vertistops are likely to need more capacity during peak hours?
- Which locations have predictable weekday demand?
- How should aircraft be repositioned before demand spikes?
- Which weather conditions reduce or reshape expected demand?
- Where should future infrastructure investment be prioritized?
The study also shows why air taxi demand prediction should be spatiotemporal. A citywide daily forecast is too blunt. Operators need a finer view: demand by station, hour, and operating condition.
Limitations to Keep in Mind
The study uses estimated air taxi demand, not observed commercial air taxi ridership. That is unavoidable for an emerging market, but it means the predictions inherit the assumptions used to generate the original demand labels. If real passengers are more price-sensitive, less willing to fly, or more affected by weather than expected, the demand patterns could change.
The model is also trained on historical New York taxi patterns. Those patterns are valuable, but urban travel behavior continues to evolve with remote work, ride-hailing, transit changes, airport access patterns, and post-pandemic commuting shifts. A deployed system would need continuous retraining with fresh data.
Even so, the paper offers a clear message: air taxi operations should be planned with data, not intuition. Machine learning can help convert scattered ride, weather, and time signals into operational demand categories that are easier to act on.
References
- Rajendran, S., Srinivas, S. and Grimshaw, T., 2021. Predicting demand for air taxi urban aviation services using machine learning algorithms. Journal of Air Transport Management, 92, 102043. https://doi.org/10.1016/j.jairtraman.2021.102043