Rule learning is one of the most natural ways to make machine learning understandable.
Instead of producing a dense mathematical model or a black-box prediction, a rule learner tries to discover patterns that can be written as:
IF conditions are true
THEN conclusion follows
That format is simple, but powerful. It is close to how people explain decisions: if a patient has these symptoms, then consider this diagnosis; if a customer buys these products, then recommend another product; if a transaction has these properties, then flag it for review.
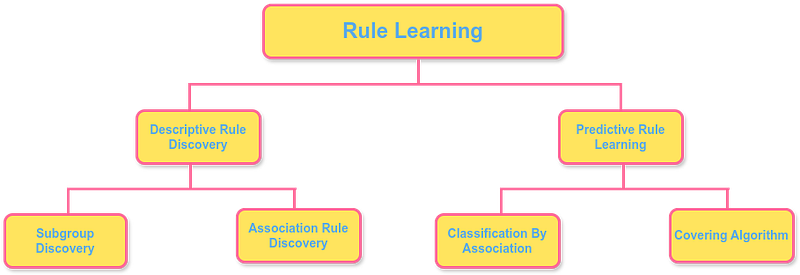
The paper A Brief Overview of Rule Learning by Johannes Fürnkranz and Tomáš Kliegr surveys this area and separates it into two major directions:
- descriptive rule discovery, where the goal is to find interesting patterns in data;
- predictive rule learning, where the goal is to build a set of rules that can classify or predict new examples.
That distinction is useful because not every rule is meant to be a classifier. Some rules are meant to explain what is happening inside a dataset. Others are meant to make decisions.
Descriptive Rule Discovery
Descriptive rule discovery is about finding patterns worth noticing.
Here, the goal is not necessarily to build a complete prediction system. A single rule may be valuable if it describes a meaningful subgroup, an unusual pattern, or a strong dependency among attributes.
For example:
IF customer buys bread and butter
THEN customer often buys milk
This kind of rule may not classify every customer, but it can still be useful for understanding behavior.
The paper highlights two major tasks in descriptive rule discovery:
- subgroup discovery,
- association rule discovery.
Both search for regularities, but they ask slightly different questions.
Subgroup Discovery
Subgroup discovery looks for groups of examples that are especially interesting with respect to a target property.
Suppose we are studying loan defaults. A subgroup rule might look like this:
IF income is below 50,000 AND credit history is short
THEN default risk is high
The rule has two parts:
- the body, or antecedent, which lists the conditions;
- the head, or consequent, which states the target pattern.
When an example satisfies all the conditions in the body, the rule “fires.” We say the example is covered by the rule.
Subgroup discovery is useful when we do not only want a prediction, but also want to understand which segments of the data behave differently from the average. In medicine, this could mean identifying a patient subgroup with unusually high risk. In marketing, it could mean finding customers with a distinct purchasing pattern.
The quality of a subgroup rule is usually judged by a mix of coverage and interestingness. A rule that applies to only one person may be too narrow. A rule that applies to everyone may be too obvious. Good subgroup rules usually sit between those extremes.
Association Rule Discovery
Association rule discovery looks for dependencies among attributes, often without a predefined target class.
The classic example comes from retail:
bread, butter -> milk, cheese
This means that transactions containing bread and butter are often also associated with milk and cheese.
Two common measures are support and confidence.
Support tells us how often the full rule appears in the dataset. If a rule has 10% support, then 10% of all transactions contain both the body and the head of the rule.
Confidence tells us how often the head appears when the body appears. If the rule has 80% confidence, then 80% of the transactions containing bread and butter also contain milk and cheese.
These measures help separate useful patterns from coincidences. A rule with high confidence but tiny support may be too rare to matter. A rule with high support but low confidence may be too weak to guide decisions.
Predictive Rule Learning
Predictive rule learning uses rules to make predictions for new examples.
One rule is rarely enough to cover an entire problem. A useful classifier usually needs a collection of rules. That collection can be organized in two main ways: as an unordered rule set or as a decision list.
An unordered rule set contains several rules without a fixed order. When a new example arrives, every rule may be checked. This creates two common problems:
- Multiple rules may fire and disagree.
- No rule may fire at all.
If multiple rules fire, the system needs a conflict-resolution strategy. It might choose the most accurate rule, the most specific rule, or a weighted vote. If no rule fires, the system often falls back to a default rule, such as predicting the majority class.
A decision list avoids some of this complexity by ordering the rules. The classifier checks rules one by one and uses the first rule that fires:
IF rule 1 matches, use rule 1
ELSE IF rule 2 matches, use rule 2
ELSE IF rule 3 matches, use rule 3
ELSE use default prediction
This makes prediction straightforward, but it also means rule order matters. A later rule may never be reached if an earlier rule already covers the example.
Classification by Association
Classification by association connects descriptive and predictive rule learning.
The basic idea is to first mine many association rules and then keep the rules whose head predicts a target class. These selected rules are ranked and combined into a classifier.
The Classification Based on Associations algorithm, or CBA, is a well-known example. It typically starts with an association-rule mining method such as Apriori, filters for rules that predict the class label, and then chooses a useful subset for classification.
This approach is attractive because it can discover many candidate patterns. But it also has limitations. Classic associative classifiers often work best with nominal attributes. Numeric attributes may need to be discretized first, which can lose information if the discretization is too coarse.
Covering Algorithm
The covering algorithm is one of the classic strategies for learning a rule set.
It is also called separate-and-conquer:
- Learn one good rule.
- Add it to the rule set.
- Remove the examples covered by that rule.
- Repeat the process on the remaining examples.
The name captures the idea. Each rule separates out part of the problem, and the algorithm keeps learning rules until the target examples are covered or a stopping condition is reached.

A good covering rule should cover many positive examples while covering few negative examples. That balance matters. A rule that covers many positives but also many negatives is too broad. A rule that covers only one positive example may be too specific.
As the rule set grows, each new rule focuses on the examples not already handled by earlier rules. The final result is a collection of logical rules that together act as a classifier.
Why Rule Learning Still Matters
Rule learning remains important because it gives us models that are readable by design.
Decision trees are also interpretable, but rule sets can sometimes be more compact. A rule can describe one useful region of the instance space without forcing the model to split every other region at the same time. This can make rule-based explanations cleaner than full tree structures.
Rules are also naturally connected to knowledge representation. In areas such as the Semantic Web and Linked Data, knowledge is often already represented in rule-like or relational form. That makes rule learning a useful tool for completing knowledge bases, discovering missing relationships, and building transparent reasoning systems.
In modern AI, rule learning fits naturally into neurosymbolic work. Neural models are powerful pattern learners, but rules offer structure, transparency, and explicit reasoning. Combining both can lead to systems that learn from data while still producing knowledge humans can inspect.
The central appeal is simple: a good rule does not only predict. It explains in a language people can read.
References
- Fürnkranz, J. and Kliegr, T., 2015, July. A brief overview of rule learning. In International Symposium on Rules and Rule Markup Languages for the Semantic Web (pp. 54-69). Cham: Springer International Publishing. DOI: 10.1007/978-3-319-21542-6_4