Given the sequence 1, 2, 4, 7, 11, 16, what comes next?
Most people do not solve this by memorizing the numbers. They look for the rule. The differences are 1, 2, 3, 4, 5, so the next difference should be 6, and the next term should be 22. In symbolic form, the sequence follows a recurrence relation: each term depends on earlier terms and the current index.
That small puzzle captures the core idea of Deep Symbolic Regression for Recurrent Sequences. The paper asks whether a Transformer can look at the first few terms of a sequence and infer the symbolic rule that generated it.
This is different from ordinary sequence prediction. A numeric model might simply predict the next few values. A symbolic model tries to recover the formula. If it succeeds, it can extrapolate much farther, because it has learned the mechanism rather than only the next step.
That distinction is what makes the work interesting. The authors are not just asking a neural network to continue a pattern. They are asking it to translate numbers into mathematical structure.
Methods
The problem can be stated simply: given the first terms of a sequence, find a function that can generate the rest.
More formally, the model sees a sequence (u_0, …, u_{n-1}) and tries to infer a recurrence relation of the form:
[ u_i = f(i, u_{i-1}, …, u_{i-d}) ]
Here, (d) is the recurrence degree. A degree of 1 means the next term depends only on the previous term. A larger degree means the rule may depend on several earlier terms.
This problem is naturally underdetermined. Many different formulas can fit a short list of numbers. So the model is encouraged, through the way the training data is generated, to prefer simpler explanations. This is the same spirit as Occam’s razor: if multiple rules explain the observed sequence, the simpler one is usually the more useful hypothesis.
The authors study two kinds of sequences:
- integer sequences, using operations such as addition, multiplication, modulo, and integer division;
- float sequences, using a larger vocabulary that includes division, square root, logarithms, exponentials, and trigonometric functions.
The float setting is harder because the operator space is larger and numerical precision matters more.

The paper compares two tasks.
In symbolic regression, the Transformer predicts the recurrence relation itself. That predicted formula is then evaluated by using it to generate future terms.
In numeric regression, the model directly predicts the next values without producing a formula. This is closer to ordinary sequence extrapolation.
The difference is subtle but important. Numeric prediction can work well for the next term or two, but errors often grow as the model extrapolates farther. Symbolic prediction has a higher bar: it must find the right rule. But once it does, it can keep generating the sequence with high precision.
Data generation
The models are trained on synthetic sequences. Each training example is created by randomly generating a recurrence relation, sampling initial values, and then computing the resulting sequence.
The process works roughly as follows:
- Determine the number of operators o by randomly choosing a value between 1 and o_{max}. Then, construct a unary-binary tree with o nodes. The complexity of the resulting expression is directly related to the number of operators.
- Populate the tree’s nodes with operators selected from those listed in Table above. It’s important to note that the tasks involving float sequences incorporate a wider variety of operators than those with integer sequences, thus broadening the scope of challenges by increasing the problem space.
- Choose a value for the recurrence degree d through random selection between 1 and d_{max}. This degree indicates the depth of recurrence; for instance, a degree of 2 signifies that u_{n+1} is dependent on u_n and u_{n-1}.
- Decide what occupies the tree’s leaves by sampling: a constant with probability p_{const}, the current index n with probability p_n, or a preceding term of the sequence u_{n-i} (where i ranges from 1 to d) with probability p_{var}.
- After determining the deepest leaf u_{n-i} in step 4, adjust the true recurrence degree d accordingly. Then, generate d initial terms of the sequence from a specified random distribution P.
- Select a length l randomly between l_{min} and l_{max} and calculate the subsequent l terms based on the initial conditions set. The effective input sequence length is thus n_{input} = d_{eff} + l.
Encodings
Transformers work with tokens, so numbers and formulas must be converted into token sequences.
Integers are represented using a base notation. Each integer becomes a sequence of tokens: a sign token followed by digit tokens. The base choice creates a tradeoff. A small base gives longer token sequences, while a large base increases the vocabulary size.
Floats are encoded with sign, mantissa, and exponent tokens. This lets the model process real-valued sequences while keeping the vocabulary finite.
Mathematical expressions are encoded in prefix notation. For example, an expression like cos(3x) can be represented as:
[cos, mul, 3, x]
This representation turns a formula tree into a sequence the Transformer can read and generate.
Results
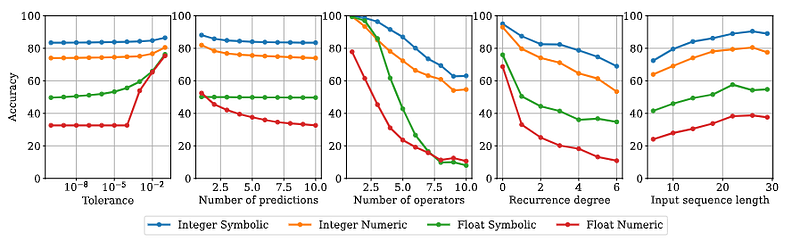
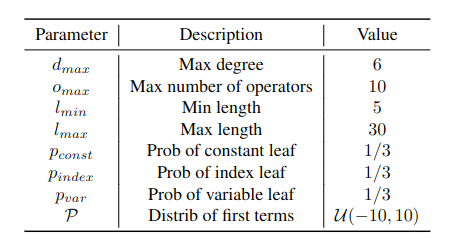
The in-distribution results show the value of predicting formulas instead of only values. For generated integer sequences with up to 10 operators, the symbolic model reached higher accuracy than the numeric model. The advantage was even clearer for float sequences, where symbolic prediction handled high-precision extrapolation better.
The reason is intuitive. If a numeric model predicts the next values directly, every additional future step is another chance for error. If a symbolic model recovers the correct recurrence relation, it can keep applying the rule.
The paper also shows that difficulty rises quickly with expression complexity. More operators, deeper recurrence, and shorter input sequences all make the task harder. This is expected: a short sequence gives fewer clues, and a complex recurrence has more possible explanations.
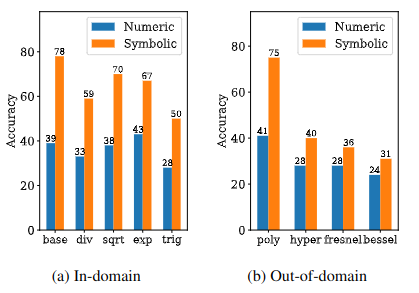
The out-of-domain experiments are especially interesting.
For integer sequences, the authors tested on a subset of the Online Encyclopedia of Integer Sequences, or OEIS. This is a difficult benchmark because many OEIS sequences do not have simple recurrence relations of the kind the model was trained to discover. Even so, the symbolic model recovered valid recurrence relations for a meaningful fraction of the sequences and outperformed Mathematica’s built-in sequence functions in the tested recurrence-prediction setting.
For float sequences, the authors tested whether the model could handle constants and functions outside its vocabulary. This is where the model becomes surprisingly creative. When it cannot directly express a constant, it may approximate it using available operations. For example, the paper reports approximations that connect numerical values to expressions involving (\pi), exponentials, or trigonometric functions.
This does not mean the model “understands” mathematics the way a human mathematician does. But it does show that a Transformer trained on symbolic sequence tasks can learn useful mathematical regularities and reuse them in unfamiliar cases.
Why It Matters
Recurrent sequences are everywhere. They appear in discrete dynamical systems, algorithms, population models, finance, physics simulations, and time-stepped scientific data. A recurrence relation is also closely related to a differential equation: it describes how a system evolves from one step to the next.
That makes this work more than a sequence-puzzle solver. It suggests a path toward models that infer symbolic dynamics from observed trajectories.
The key lesson is that symbolic prediction and numeric prediction have different strengths. Numeric prediction is often easier and can be strong for short horizons. Symbolic prediction is harder, but when it succeeds, it gives something more valuable: a reusable rule.
That rule can be inspected, tested, simplified, and connected to existing mathematical knowledge.
Limitations
The paper is also careful about limitations. The models are trained on synthetic recurrence relations, so generalization depends on how well the training generator covers the kinds of rules seen at test time. If a sequence is generated by a process outside the model’s vocabulary or training distribution, the model can fail.
There is also no guarantee that the predicted formula is the true underlying rule. A finite sequence can always be explained by many possible expressions. The best we can ask is whether the formula is simple, predictive, and useful on future terms.
Still, the paper is an important step. It shows that Transformers can do more than predict the next token or next number. With the right representation and training setup, they can produce symbolic hypotheses about the process behind a sequence.
References
- d’Ascoli, S., Kamienny, P.A., Lample, G. and Charton, F., 2022. Deep symbolic regression for recurrent sequences. arXiv preprint arXiv:2201.04600. PDF
- https://symbolicregression.metademolab.com/
- https://www.youtube.com/watch?v=1HEdXwEYrGM