Distilling Free-Form Natural Laws
from Experimental Data
Imagine watching a pendulum swing, recording its motion frame by frame, and then asking a computer: can you find the law hiding inside this movement?
Not just a curve that predicts the next position. Not just a black-box model that says, “trust me.” A real mathematical expression: something compact, readable, and close to the kind of equation a physicist would write down.
That is the central idea behind Michael Schmidt and Hod Lipson’s 2009 paper, Distilling Free-Form Natural Laws from Experimental Data. The paper asks a bold question: can an algorithm discover physical laws directly from raw experimental observations, without being told physics, geometry, or even what kind of equation to look for?
Their answer is surprisingly powerful. Using motion-tracking data from systems such as harmonic oscillators, pendulums, and chaotic double pendulums, the algorithm rediscovered meaningful laws: energy relationships, geometric constraints, Newtonian equations of motion, and conservation-like quantities. In some cases, it found equations equivalent to Hamiltonians and Lagrangians, the mathematical language used to describe the dynamics of physical systems.
The exciting part is not simply that a computer fitted data. We already know computers can do that. The exciting part is that it searched for equations that humans could inspect, interpret, and connect back to physical meaning.
Why This Problem Is Hard
Modern science is very good at producing data. Sensors are faster, cameras are sharper, simulations are larger, and experiments can record enormous amounts of detail. But turning all that data into concise scientific understanding is still difficult.
A neural network might learn to predict the motion of a pendulum very accurately, but the learned model may not tell us much about why the pendulum moves the way it does. A traditional regression model can fit parameters, but only after a human decides the form of the equation. If we already know the equation structure, much of the discovery has already happened.
The harder challenge is different: search for the equation itself.
That means the algorithm must explore possible mathematical expressions made from variables, constants, operators, and functions such as sine and cosine. It must decide whether one expression is more meaningful than another. And it must avoid being fooled by trivial formulas that look constant but explain nothing.
For example, a mathematical expression can be numerically invariant for uninteresting reasons. It might be a disguised identity or a formula that barely changes over the observed range of data. The mere fact that something stays nearly constant is not enough to call it a law of nature.
This is where the paper’s key insight becomes important: a useful law should not only remain stable; it should also explain relationships among the system’s changing parts.
Symbolic Regression
The engine behind this work is symbolic regression.
In ordinary regression, we usually begin with a fixed template. We might assume the data follows a line, a polynomial, or a particular physical model, and then estimate the unknown coefficients. Symbolic regression is more open-ended. It searches over both the structure of the equation and its parameters.
The algorithm begins with a population of candidate expressions built from mathematical ingredients:
- variables measured from the experiment,
- constants,
- arithmetic operators such as addition, multiplication, and division,
- functions such as sine and cosine.
Then it evolves them. Promising expressions are recombined, mutated, simplified, and tested again. Over time, the population moves toward equations that describe the data better.
This is already useful for discovering explicit equations or differential equations. But Schmidt and Lipson were after something subtler. They wanted equations that describe deeper structure: conserved quantities, invariant relationships, manifolds, and energy-like laws. These are not always direct predictions of the next data point. They are constraints that reveal the system’s inner organization.
The Trick: Look at Relationships Between Changes
The paper’s clever move is to judge candidate equations by how well they capture relationships between derivatives.
Suppose we observe two variables, (x(t)) and (y(t)), over time. The data tells us how these variables change relative to each other. A candidate equation (f(x, y)) also implies relationships between changes, because we can differentiate it symbolically.
If the relationships implied by the equation match the relationships observed in the experimental data, the equation is probably describing something real about the system. It is not just a pretty formula. It is connected to the dynamics.
This criterion helps separate meaningful laws from mathematical clutter. It also makes the method flexible. Depending on which variables are provided, the algorithm can be nudged toward different kinds of discoveries:
- with only position data, it may find geometric constraints or manifolds;
- with position and velocity data, it may find energy laws;
- with acceleration data, it may recover force laws or equations of motion.
In other words, the algorithm does not need to be told, “find the Hamiltonian” or “find Newton’s law.” It searches for compact expressions that explain the structure in the observed changes.
Process
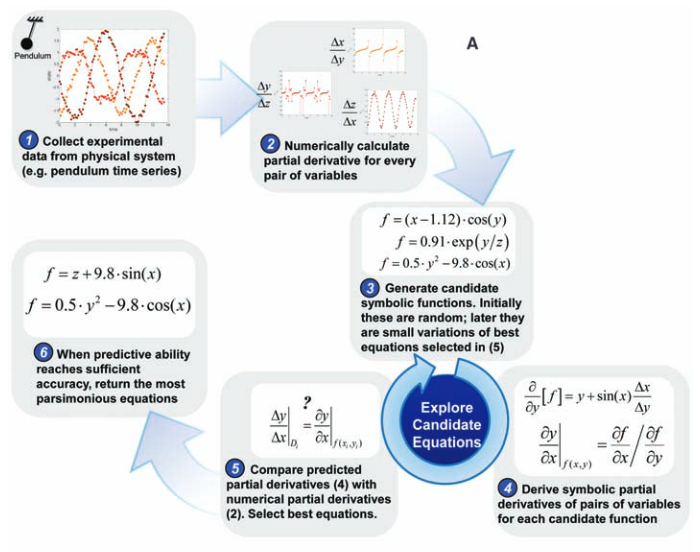
First, calculate partial derivatives between variables from the data, then search for equations that may
describe a physical invariance. To measure how well an equation describes an invariance, derive the same
partial derivatives symbolically to compare with the data.
The workflow is simple to describe, even if the search itself is computationally demanding.
First, collect time-series data from a physical system. In the paper, this included motion-tracking data from an air-track oscillator, a pendulum, and a double pendulum. Next, calculate quantities such as position, velocity, and acceleration from the recorded motion. Then let symbolic regression search through possible equations.
Each candidate equation is scored in two ways. It must be accurate, meaning it should predict the derivative relationships seen in withheld data. But it must also be simple. A giant equation that memorizes noise is not a satisfying scientific law. A short equation that captures the essential structure is much more valuable.
This creates a tradeoff between accuracy and parsimony. The algorithm does not return just one answer. It returns a small set of candidates along the Pareto front: equations where improving accuracy would require adding complexity, and simplifying the equation would reduce accuracy.
That is a useful way to think about scientific theory itself. A good law is not merely a formula that fits. It is a compact explanation that earns its complexity.
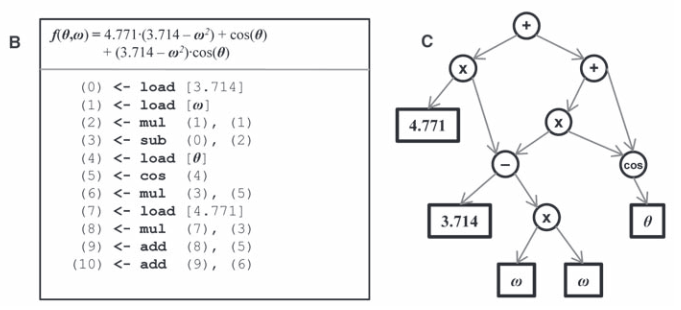
Results
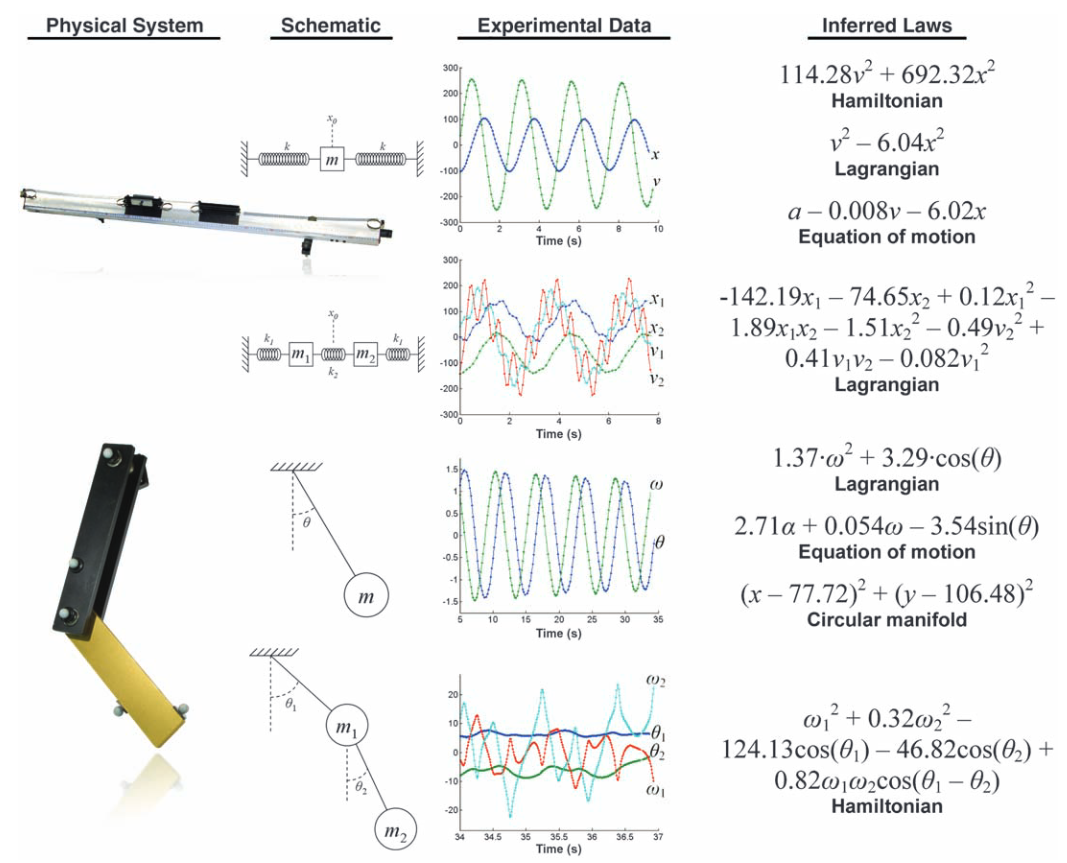
The experiments become especially interesting when the systems grow more complex.
For a simple harmonic oscillator, the algorithm could recover familiar energy and force relationships. For a pendulum, it could discover that the motion is constrained to a circle when given only position data. When velocity was included, it moved toward energy-like expressions. When acceleration was included, it could recover equations related to Newton’s second law.
The double pendulum was the real stress test. A double pendulum can behave chaotically, and its motion is much harder to summarize with a neat equation. Yet the algorithm still found meaningful structure. With position and velocity data, it converged toward energy laws such as the Hamiltonian. In some high-energy chaotic cases, it fixated on angular momentum, a simpler approximate law that becomes more relevant when gravity is less dominant compared with rapid motion.
This is an important detail: the algorithm did not behave like a magical oracle. It made approximations when the data emphasized certain regimes, and it depended on the mathematical building blocks it was allowed to use. If sine and cosine were removed from its toolbox, it built polynomial approximations instead, much like a Taylor expansion. That behavior is not a weakness; it makes the method feel more scientifically realistic. Discovery depends on the data we collect, the variables we measure, and the concepts available to express what we see.
The paper also shows a promising way to scale the search. Laws discovered in simpler systems can be used to seed the search for more complex systems. When the authors reused terms from simpler pendulum and oscillator equations to initialize the double-pendulum search, the computation time dropped dramatically. This suggests something close to scientific learning: build an alphabet from simple systems, then reuse that alphabet to understand harder ones.
Why It Matters
This paper is exciting because it sits between two worlds.
On one side, we have black-box machine learning systems that can model complicated patterns but often struggle to explain themselves. On the other side, we have classical scientific equations that are concise, interpretable, and deeply explanatory. Schmidt and Lipson’s work shows a path between them: use computation not just to predict, but to propose symbolic laws that humans can inspect.
The method does not replace scientists. The authors are clear about this. Even when an algorithm finds an equation, humans still need to interpret it, connect it to units and physical meaning, decide whether it is fundamental or approximate, and design new experiments to test it.
But it can change the pace of discovery. In fields overflowing with data, from systems biology to cosmology, algorithms like this could help researchers notice structure that would otherwise remain buried. They can generate candidate laws, highlight useful variables, and point scientists toward the parts of a system that deserve deeper attention.
The most compelling idea is that scientific discovery may be partly automated without becoming less human. The computer can search the vast landscape of possible equations. The scientist can ask better questions, challenge the results, and decide what the equations actually mean.
That partnership is the real story of this paper.
References
- Schmidt, M. and Lipson, H., 2009. Distilling free-form natural laws from experimental data. Science, 324(5923), pp.81-85. PDF