Reinforcement learning (RL) is built around a simple idea: an agent learns by interacting with an environment. It observes a state, takes an action, receives a reward, and gradually improves its behavior.
Deep reinforcement learning (DRL) made this idea powerful by adding neural networks. Instead of storing every state-action value in a table, a deep model can approximate policies or value functions from high-dimensional data such as images, sensor streams, or game states.
But DRL also inherits several hard problems: it can be data-hungry, difficult to interpret, sensitive to reward design, and hard to verify in safety-critical environments.
Neurosymbolic reinforcement learning tries to address these limitations by combining three ingredients:
- neural learning, for perception and function approximation
- symbolic reasoning, for structure, rules, logic, and interpretability
- reinforcement learning, for sequential decision-making through interaction
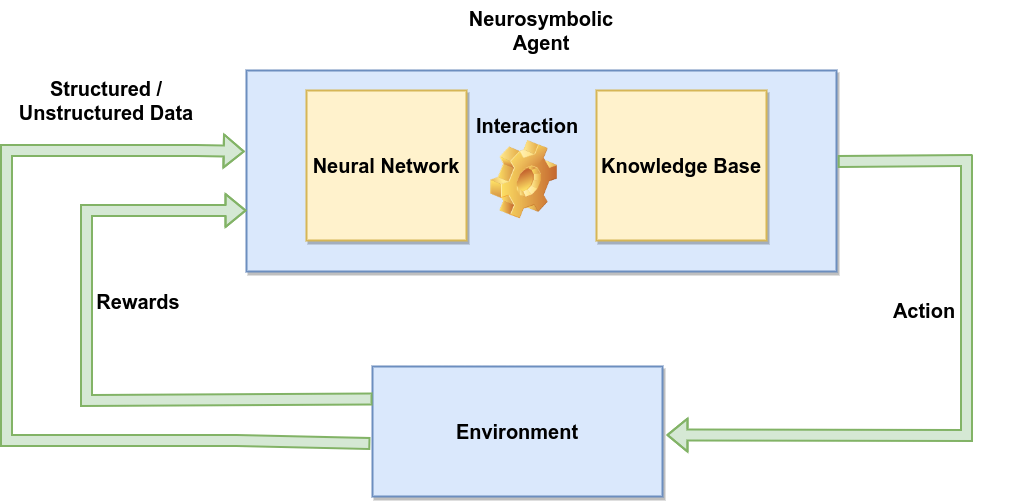
This article is based on the survey paper “Neurosymbolic Reinforcement Learning and Planning: A Survey”, which organizes the field into three broad categories: Learning for Reasoning, Reasoning for Learning, and Learning-Reasoning.
Why Reinforcement Learning Needs More Structure
RL has achieved major milestones: game playing, robotic control, multi-agent systems, recommendation, resource allocation, and decision-making under uncertainty.
However, many RL successes happen in environments where exploration is cheap and repeated failures are acceptable. Real-world environments are different.
In practice, RL faces several recurring difficulties:
- Sample inefficiency: agents may need huge numbers of interactions to learn.
- Reward design: poorly shaped rewards can lead to unintended behavior.
- Sparse feedback: some tasks only provide reward after a long sequence of actions.
- Poor transfer: policies trained in one environment may fail in another.
- Limited interpretability: learned policies can be hard to inspect or verify.
- Unsafe exploration: real systems cannot allow arbitrary trial and error.
Symbolic reasoning can help because many tasks already contain structure: rules, constraints, goals, temporal logic, programs, graphs, plans, or domain knowledge.
Neurosymbolic RL asks how we can use that structure without losing the flexibility of neural learning.
What Makes an RL System Neurosymbolic?
A standard RL system has an agent, an environment, states, actions, rewards, and a policy. A neurosymbolic RL system adds symbolic structure somewhere in that loop.
That symbolic structure may appear as:
- logical rules
- formal specifications
- knowledge graphs
- symbolic options or skills
- programmatic policies
- planning modules
- automata
- causal models
- domain constraints
The neural part may still handle perception, value estimation, policy learning, or representation learning. The symbolic part may guide learning, verify behavior, shape rewards, or make the learned policy more understandable.
The result is not one single algorithm. It is a design space.
A Useful Taxonomy
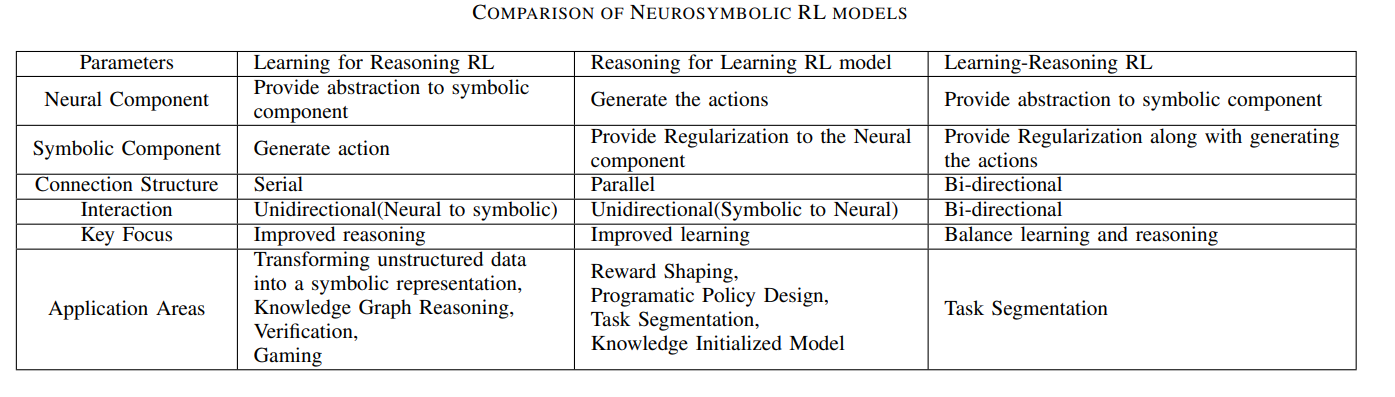
The survey organizes neurosymbolic RL into three main categories:
- Learning for Reasoning
- Reasoning for Learning
- Learning-Reasoning
These categories are useful because they describe the direction of help between the neural and symbolic components.
1. Learning for Reasoning
In Learning for Reasoning, the learning component helps the symbolic component reason more effectively.
The neural model may process raw or unstructured data and convert it into a symbolic representation. The symbolic system can then reason over that representation.
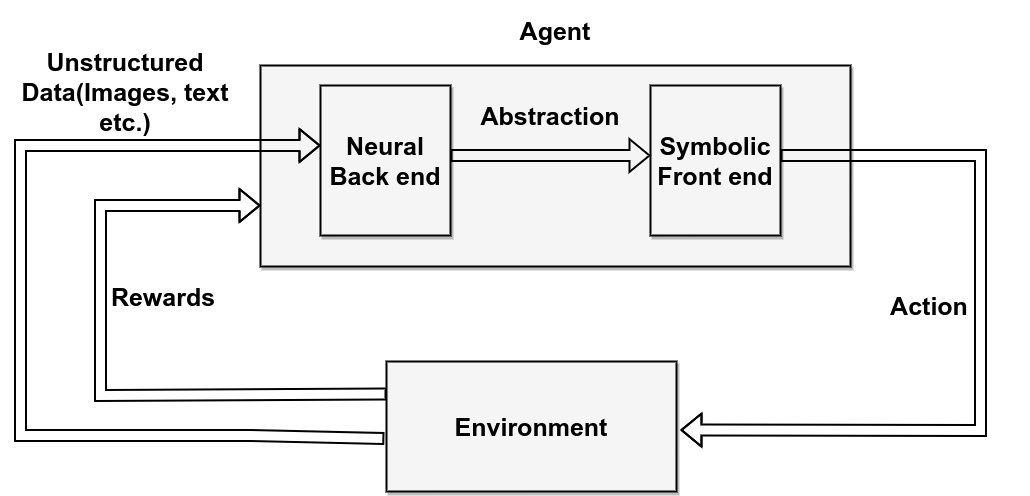
This is useful when the environment contains information that is difficult to represent symbolically at first.
For example, a robot may perceive the world through cameras. A neural model can detect objects, locations, or relations. A symbolic planner can then reason over those extracted concepts to choose actions.
In this setup, the neural component acts like a bridge from messy data to structured reasoning.
Where It Helps
Learning for Reasoning is useful for:
- processing unstructured observations
- extracting symbolic states from images or sensor data
- supporting knowledge graph reasoning
- compressing a large symbolic search space
- making policies easier to verify after learning
The main advantage is that it allows symbolic reasoning to operate in environments where symbolic inputs are not directly available.
The main challenge is reliability. If the neural component extracts the wrong symbols, the reasoning system may produce a logically valid but practically wrong decision.
2. Reasoning for Learning
In Reasoning for Learning, the symbolic component helps the RL agent learn better.
Here, symbolic knowledge can guide exploration, shape rewards, restrict actions, initialize policies, or provide high-level plans.
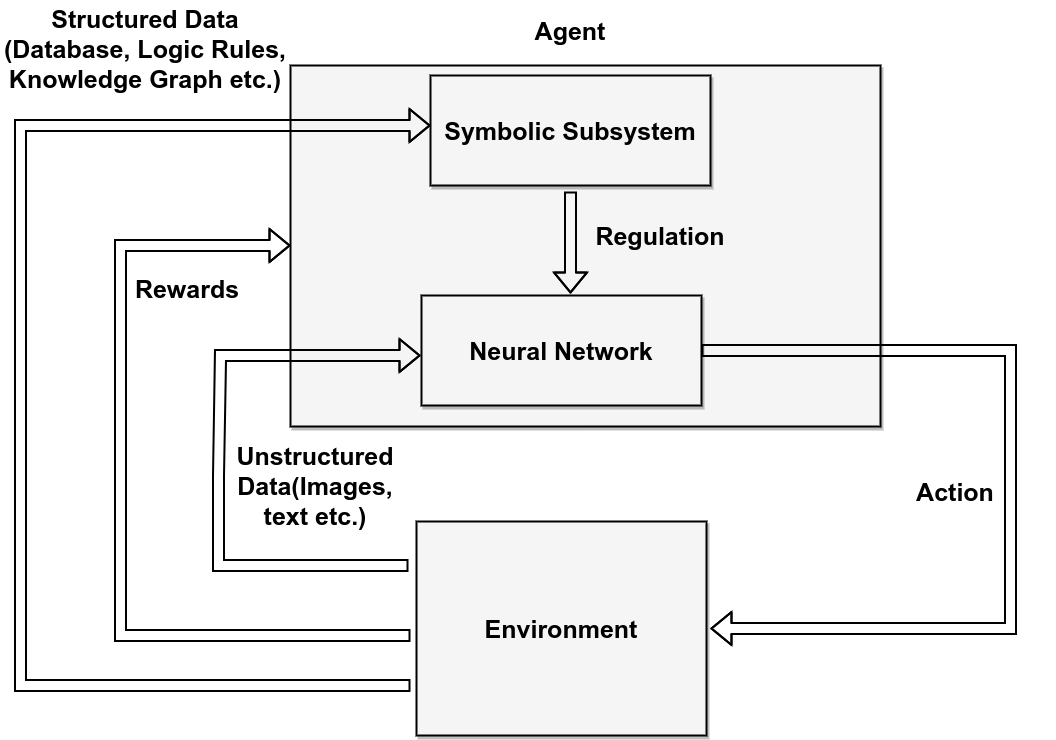
This is valuable because pure DRL often wastes experience exploring actions that are obviously bad from a domain perspective.
For example, in a navigation task, symbolic knowledge may encode that walls cannot be crossed, unsafe regions must be avoided, or a goal requires completing subgoals in order. The RL agent still learns, but it learns inside a better-structured space.
Where It Helps
Reasoning for Learning is useful for:
- reward shaping
- safe exploration
- reducing action-space complexity
- injecting expert knowledge
- guiding Monte Carlo tree search
- encoding temporal logic or task specifications
- improving sample efficiency
The benefit is practical: the agent can learn faster and avoid some unsafe or meaningless actions.
The challenge is bias. If symbolic knowledge is incomplete or wrong, it can constrain learning too much or push the agent toward suboptimal behavior.
3. Learning-Reasoning
In Learning-Reasoning, neural and symbolic components interact bidirectionally.
The neural part helps build or refine symbolic representations, while the symbolic part guides or constrains the neural learner. Information flows both ways.
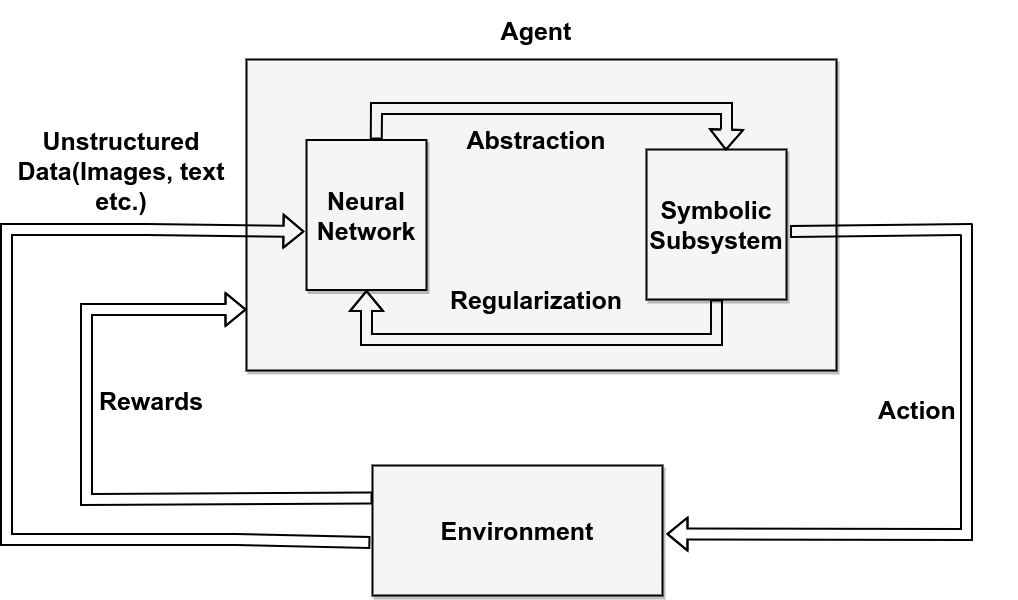
This is the most integrated form of neurosymbolic RL. It is also the hardest to design.
In an ideal system, the agent learns from experience, abstracts useful concepts, reasons over those concepts, and uses reasoning to improve future learning.
Where It Helps
Learning-Reasoning is useful for complex domains where neither neural learning nor symbolic reasoning is enough alone.
Examples include:
- robotics with perception and planning
- autonomous driving decision modules
- hierarchical task learning
- programmatic policy synthesis
- causal reinforcement learning
- multi-step reasoning under uncertainty
The advantage is flexibility. The system can learn from data while still using structure.
The challenge is coordination. The neural and symbolic components must exchange information in a form that is meaningful, stable, and trainable.
Why This Matters for Reward Shaping
Reward design is one of the most difficult parts of RL.
Sparse rewards can make learning slow because the agent receives useful feedback only after completing a task. Dense shaped rewards can speed up learning, but they can also create bias or unintended shortcuts.
Neurosymbolic RL gives another option: use symbolic knowledge to shape rewards in a more structured way.
For example, a temporal logic formula can describe what a successful task looks like. An automaton can track progress toward that task. The agent can then receive intermediate guidance based on meaningful subgoal progress rather than arbitrary reward engineering.
This can make learning faster and more aligned with the actual objective.
Planning and Programmatic Policies
Another important direction is programmatic policy learning.
Instead of representing a policy only as a neural network, the system may learn or extract a policy in a more interpretable form, such as a program, decision structure, or symbolic option hierarchy.
This matters because programmatic policies can sometimes be:
- easier to inspect
- easier to verify
- easier to transfer
- easier to debug
- more compact than neural policies
In safety-critical systems, a policy that can be inspected is often more useful than a black-box policy with slightly better benchmark performance.
Application Areas
The survey identifies many areas where neurosymbolic RL can be useful.
Robotics
Robotics needs perception, control, planning, and safety. Neural models can process sensor data, while symbolic planners can reason about objects, tasks, constraints, and action sequences.
This is one of the most natural settings for neurosymbolic RL because robots operate in physical environments where random exploration can be dangerous.
Autonomous Driving
Driving requires perception and rule-based reasoning. A vehicle must detect lanes, vehicles, pedestrians, and signs, but it must also obey traffic rules, reason about safety, and plan actions.
Neurosymbolic RL can support decision modules that combine learned behavior with formalized driving rules and constraints.
Knowledge Graph Reasoning
RL can be used to reason over paths in knowledge graphs. The agent learns to navigate from an entity to an answer through relational links.
Symbolic graph structure provides interpretability, while RL provides a way to search through large relational spaces.
Formal Verification and Safe Exploration
Symbolic methods can support formal specifications, model checking, or constraints that prevent unsafe behavior.
This is especially important when an RL agent operates in environments where mistakes are costly.
Healthcare, Networks, and Industrial Systems
In domains such as healthcare, communication networks, IoT, finance, and industrial control, decisions must often follow rules and constraints. Neurosymbolic RL can combine learning with domain logic to make decisions more transparent and reliable.
Benefits
The main benefits of neurosymbolic RL are:
- Interpretability: symbolic policies, rules, or plans can make agent behavior easier to understand.
- Sample efficiency: prior knowledge can reduce unnecessary exploration.
- Safety: symbolic constraints can block invalid or unsafe actions.
- Reward shaping: formal structure can guide the agent toward meaningful subgoals.
- Transferability: abstract symbolic representations may generalize across tasks.
- Verification: symbolic components can make parts of the system easier to analyze.
These benefits are especially relevant when RL moves from games and simulations into real-world systems.
Challenges
Neurosymbolic RL also has open challenges.
First, symbolic knowledge is not always available. Building rules, ontologies, programs, or specifications can require domain expertise.
Second, neural and symbolic components use different representations. Connecting continuous neural embeddings with discrete symbols remains difficult.
Third, symbolic systems can be brittle. If the rules are incomplete, the system may reason incorrectly.
Fourth, scaling symbolic reasoning to large environments is hard.
Fifth, evaluation is difficult. A model may be interpretable but less accurate, or accurate but less verifiable. Choosing the right tradeoff depends on the application.
Finally, real-world deployment requires robustness under uncertainty, noisy observations, distribution shift, and changing objectives.
Takeaway
Neurosymbolic reinforcement learning is important because it addresses a weakness of pure DRL: learning from interaction is powerful, but it often lacks structure.
Symbolic reasoning can provide that structure through rules, constraints, plans, programs, knowledge graphs, and formal specifications. Neural learning can provide flexibility and perception. RL can provide sequential decision-making.
The field is still developing, but the direction is clear:
The next generation of RL systems will need to learn, reason, and act under constraints. Neurosymbolic RL is one path toward that goal.
Reference
- Acharya, K., Raza, W., Dourado, C., Velasquez, A., & Song, H. H. (2023). Neurosymbolic Reinforcement Learning and Planning: A Survey. IEEE Transactions on Artificial Intelligence. doi: 10.1109/TAI.2023.3311428