Long sequence time-series forecasting is one of those problems that looks simple until the prediction horizon becomes long.
Predicting the next hour of electricity demand is one problem. Predicting the next week, month, or season is a very different problem. The model now has to understand long-range patterns, seasonal effects, delayed dependencies, and changing local behavior, all while staying computationally practical.
That is the setting of the paper “Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting”, presented at AAAI 2021. The paper proposes Informer, a Transformer-based architecture designed specifically for long sequence time-series forecasting (LSTF).

The key idea is not simply to use a Transformer for time series. The key idea is to make the Transformer usable when both the input sequence and the forecast horizon are long.
Informer does this through three design choices:
- ProbSparse self-attention to reduce attention cost.
- Self-attention distilling to handle long inputs through stacked encoder layers.
- A generative-style decoder to predict long output sequences in one forward pass.
Together, these changes make Informer an important early architecture for efficient long-horizon forecasting.
Why Long Sequence Forecasting Is Hard
Time-series forecasting appears in energy systems, finance, weather, transportation, sensor networks, disease modeling, supply chains, and many other domains.
Traditional forecasting methods often work well for short horizons. But when we ask the model to forecast far into the future, several problems appear:
- The model must remember useful information from far back in the input.
- Errors can accumulate over long prediction windows.
- Inference becomes slow if the model predicts one step at a time.
- Memory usage grows when the model attends over long sequences.
The Informer paper illustrates this with an LSTM forecasting electrical transformer temperature. As the prediction length grows, the mean squared error rises and inference speed drops sharply.
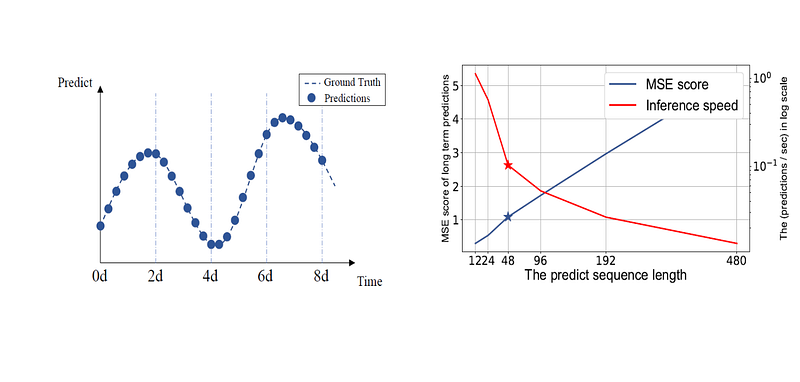
This is the core motivation for Informer: long-horizon forecasting needs both long-range dependency modeling and efficient computation.
Long Sequence Forecasting vs. Long Sequence Input Learning
It is useful to separate two related but different problems.
Long sequence input learning asks a model to understand a long input. For example, a model may read an entire book and classify its genre, summarize it, or answer a question about it.

Long sequence time-series forecasting asks a model to predict a long future sequence from a long historical sequence. Here, the model must connect past and future over time.
In other words:
- Long sequence input learning focuses on understanding long inputs.
- Long sequence forecasting focuses on predicting long outputs from long inputs.
Informer is mainly designed for the second problem.
Why Transformers Are Attractive for Forecasting
Transformers are attractive because self-attention creates direct connections between positions in a sequence. Unlike recurrent models, where information flows step by step, attention can connect distant points more directly.
This is useful in time series. A temperature reading today may depend on patterns from yesterday, last week, or a similar time in a previous cycle. Attention gives the model a mechanism to look across the sequence and decide which parts matter.
This is why Transformers became powerful in natural language processing and computer vision, and why researchers started applying them to forecasting.
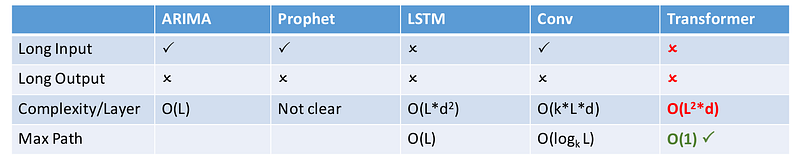
But vanilla Transformers have a major weakness for long sequences: standard self-attention has quadratic complexity. If the sequence length is L, attention compares every position with every other position, giving roughly O(L^2) time and memory cost.
That is manageable for short sequences. It becomes a serious bottleneck for long time-series forecasting.
The Three Problems Informer Solves
The paper identifies three limitations of vanilla Transformers for LSTF.
First, self-attention is expensive. Computing all query-key interactions requires quadratic time and memory.
Second, stacking encoder layers creates a memory bottleneck. If each layer carries long sequence representations forward, memory usage grows quickly.
Third, step-by-step decoding is slow. If the model predicts one future point at a time, long output sequences become expensive and error accumulation becomes a concern.
Informer is designed around these three problems.
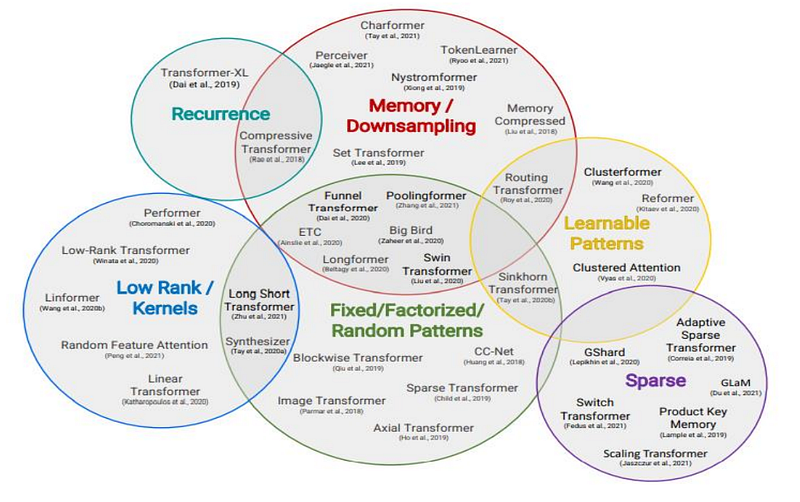
1. ProbSparse Self-Attention
The first contribution is ProbSparse self-attention.
The intuition is that not all queries in self-attention are equally important. In many attention maps, only a small number of query-key interactions carry most of the useful information. Many others contribute little.
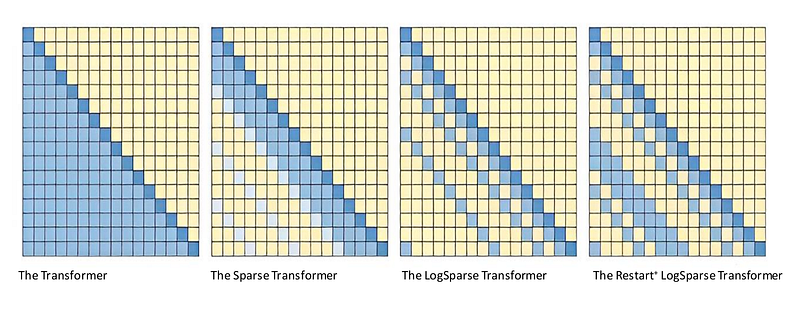
The paper observes that attention scores often follow a long-tail pattern. A few dominant pairs matter a lot, while many pairs are relatively uninformative.
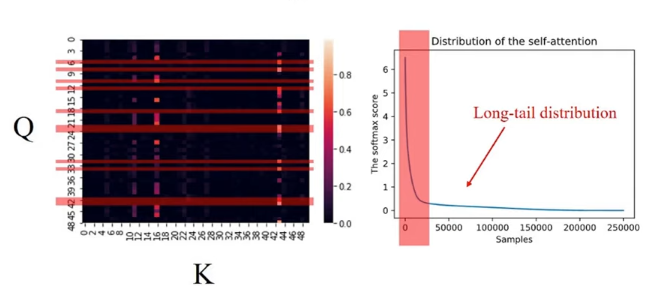
ProbSparse attention tries to focus computation on the most informative queries. Instead of computing full attention for every query, it selects the queries that are likely to have the most concentrated, non-uniform attention distributions.
The rough idea is:
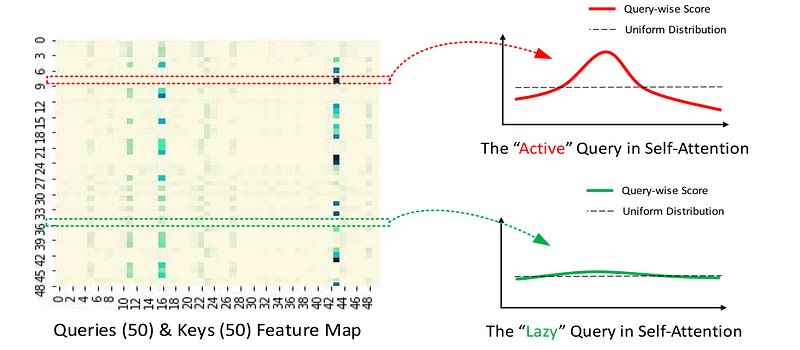
- active queries have strong attention to a small set of keys
- lazy queries behave closer to uniform attention
- computing attention for active queries preserves most of the useful dependency information
The result is a self-attention mechanism with approximately O(L log L) time and memory complexity instead of O(L^2).

This is the main efficiency gain in Informer. It makes long input sequences more tractable while trying to preserve the useful alignment behavior of attention.
2. Self-Attention Distilling
The second contribution is self-attention distilling.
Even with sparse attention, stacking many encoder layers over long sequences can still be costly. Informer addresses this by progressively reducing the sequence length between encoder layers.
The distilling operation uses convolution and pooling to keep dominant features while shortening the sequence representation. In practical terms, the model compresses the feature map as it moves deeper into the encoder.
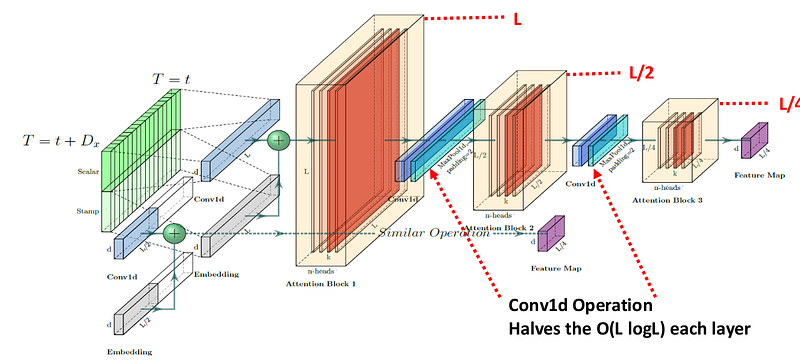
This helps the encoder handle long inputs without carrying the full-length sequence through every layer.
The architecture also uses multiple encoder stacks with different input lengths. This gives the model a way to combine information from different scales: longer context from larger inputs and more compact representations from distilled layers.
3. Generative-Style Decoder
The third contribution is the generative-style decoder.
A common encoder-decoder model predicts future values step by step. That can be slow for long forecast horizons. It can also accumulate error because each prediction may depend on previous predicted values.
Informer avoids this by predicting the entire output sequence in one forward pass.
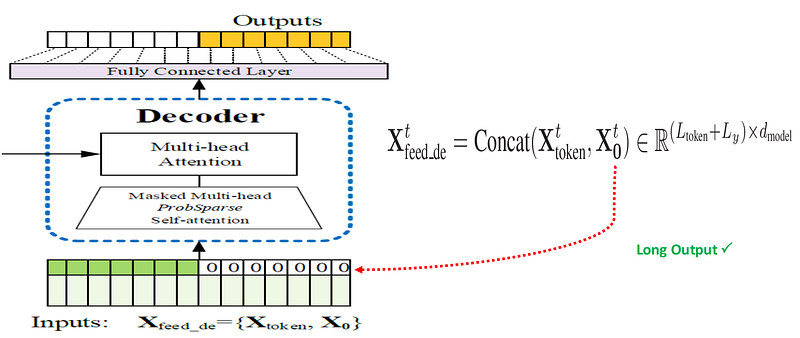
The decoder receives two parts:
- a known start token sequence from the recent past
- placeholder positions for the future values to be predicted
The model then generates the full forecast sequence directly. This design is one reason Informer is much faster during inference than models that decode one point at a time.
Informer Architecture
Putting the pieces together, Informer is an encoder-decoder architecture adapted for long-horizon forecasting.
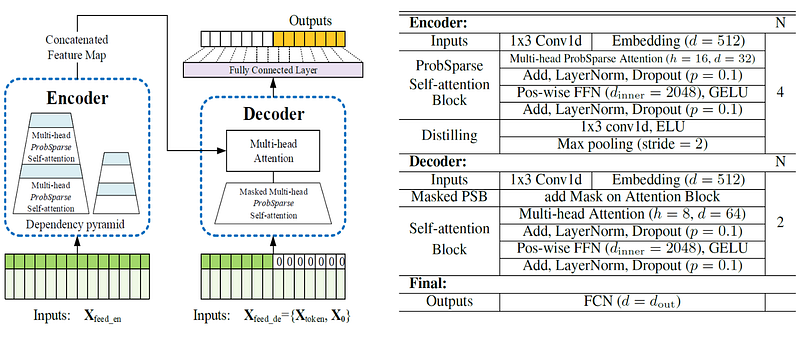
The encoder receives long historical inputs and uses ProbSparse attention plus distilling to build efficient long-range representations. The decoder receives a start sequence and future placeholders, then produces the forecast in a single forward pass.
This architecture directly targets the three bottlenecks:
- ProbSparse attention reduces attention cost.
- Distilling reduces encoder memory pressure.
- Generative decoding avoids slow autoregressive prediction.
Experiments
The paper evaluates Informer on several large-scale time-series datasets:
- ETT, electricity transformer temperature data.
- ECL, electricity consuming load data.
- Weather, measurements from many locations.
- Other forecasting settings involving univariate and multivariate prediction.
The baselines include classical time-series models, recurrent models, convolutional sequence models, and Transformer variants such as Reformer and LogSparse Transformer.
The evaluation uses common forecasting metrics:
- MSE, mean squared error.
- MAE, mean absolute error.
The experiments are designed around increasingly long prediction horizons, which is exactly where the LSTF problem becomes difficult.
What the Results Show
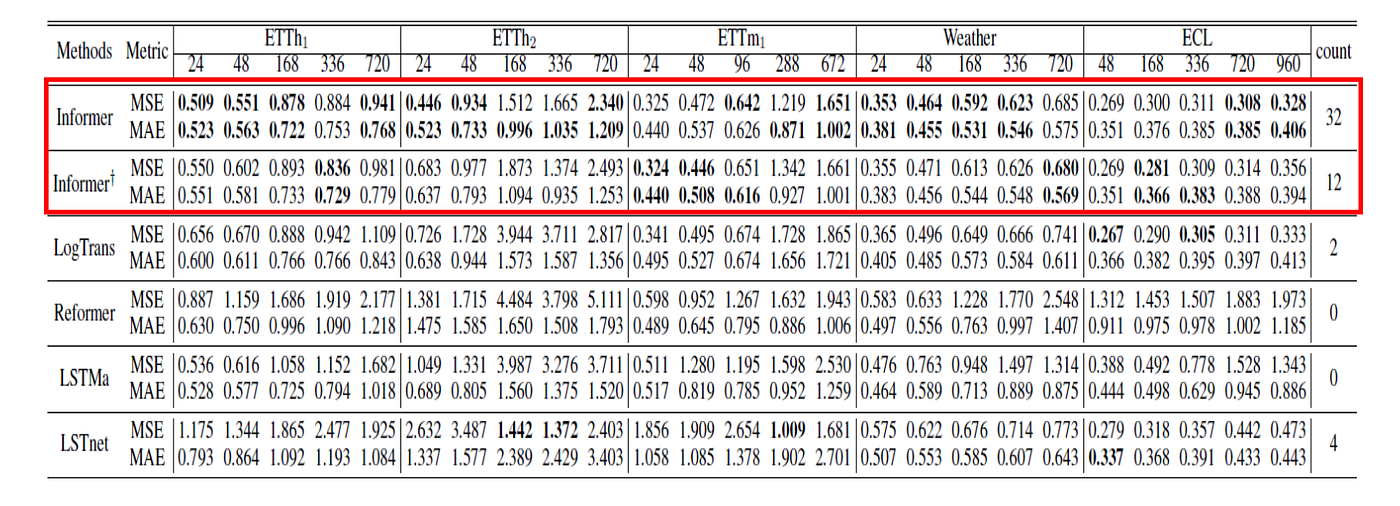
The main empirical result is that Informer performs well as the prediction horizon becomes long.
For univariate forecasting, Informer produces lower errors across many settings and maintains smoother performance as the horizon increases.
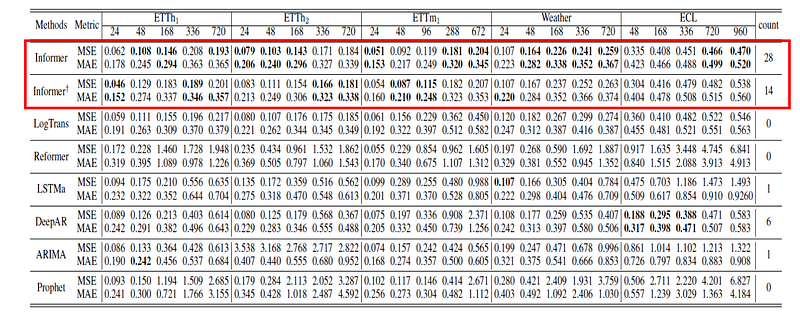
For multivariate forecasting, the same general pattern holds. Informer remains competitive and often outperforms recurrent, convolutional, and Transformer-based baselines.
The paper also studies different time granularities. This matters because forecasting at minute-level resolution and hourly resolution can expose different temporal patterns.
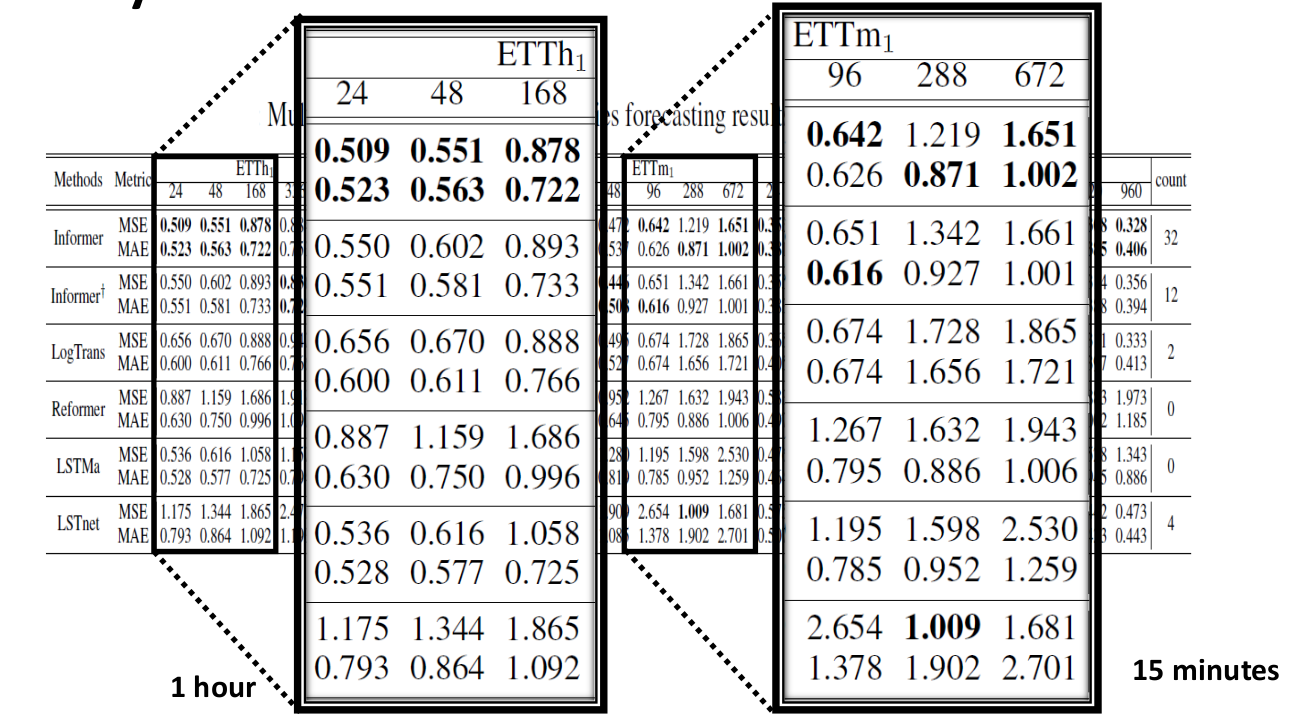
The broader result is not just that Informer improves accuracy. It also improves the practicality of Transformer-style forecasting for long sequences.
Ablation Studies
The ablation studies are important because they show why each component matters.
ProbSparse Attention
When compared with other efficient attention mechanisms, ProbSparse attention performs well and avoids some memory failures that occur when implementations still depend on full attention masks.
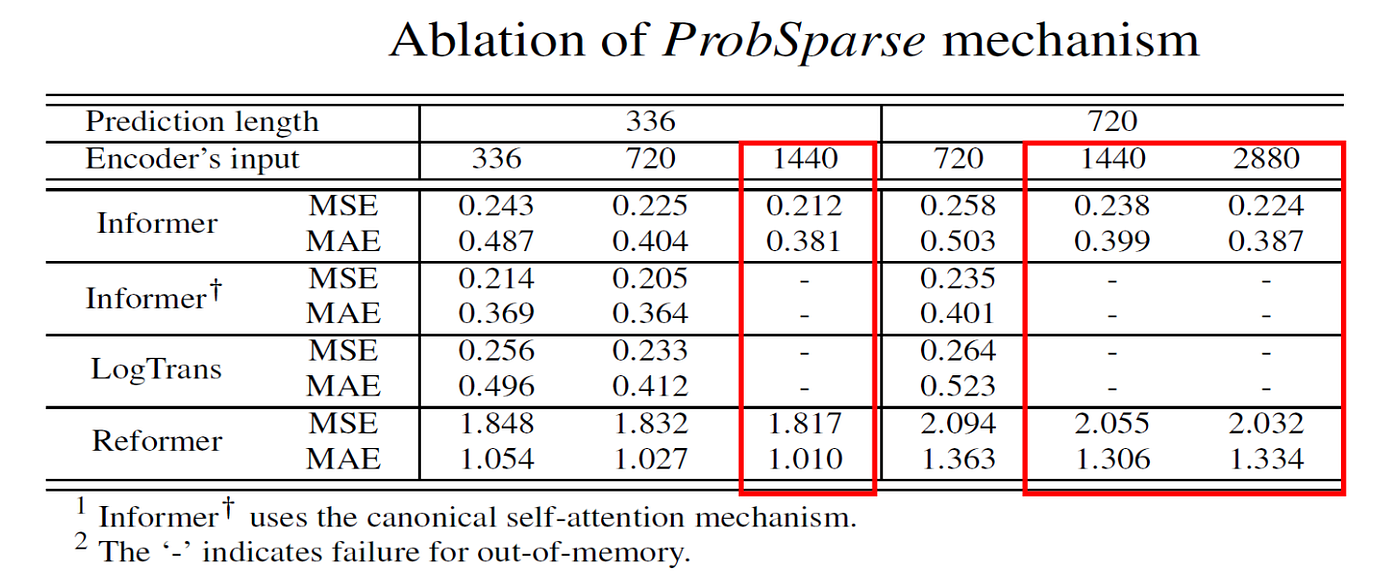
This supports the paper’s query sparsity assumption: many attention computations are redundant, and focusing on dominant queries can preserve forecasting performance.
Self-Attention Distilling
Removing distilling makes the model more likely to run out of memory on longer inputs.
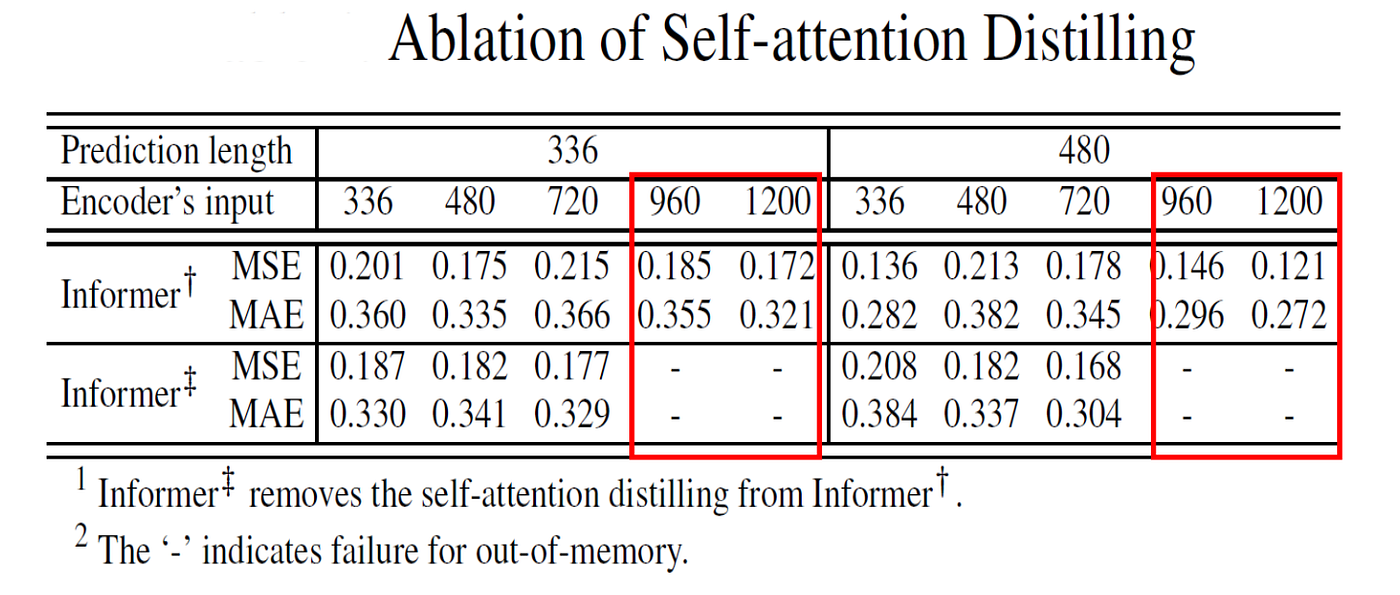
This supports the role of distilling as a practical mechanism for long input processing.
Generative Decoder
The generative decoder helps the model avoid slow dynamic decoding and reduces the problem of error accumulation over long outputs.
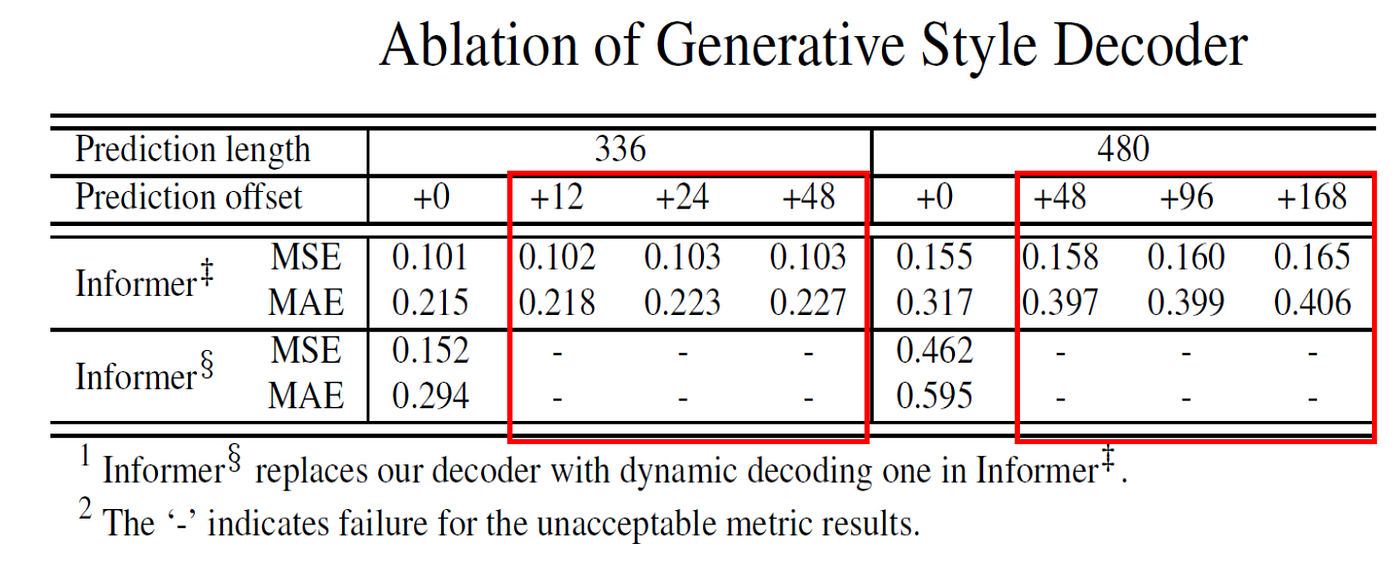
This is especially important in long-horizon forecasting because predicting one future value at a time can become both slow and fragile.
Computational Efficiency
Informer is designed not only for accuracy but also for efficiency.
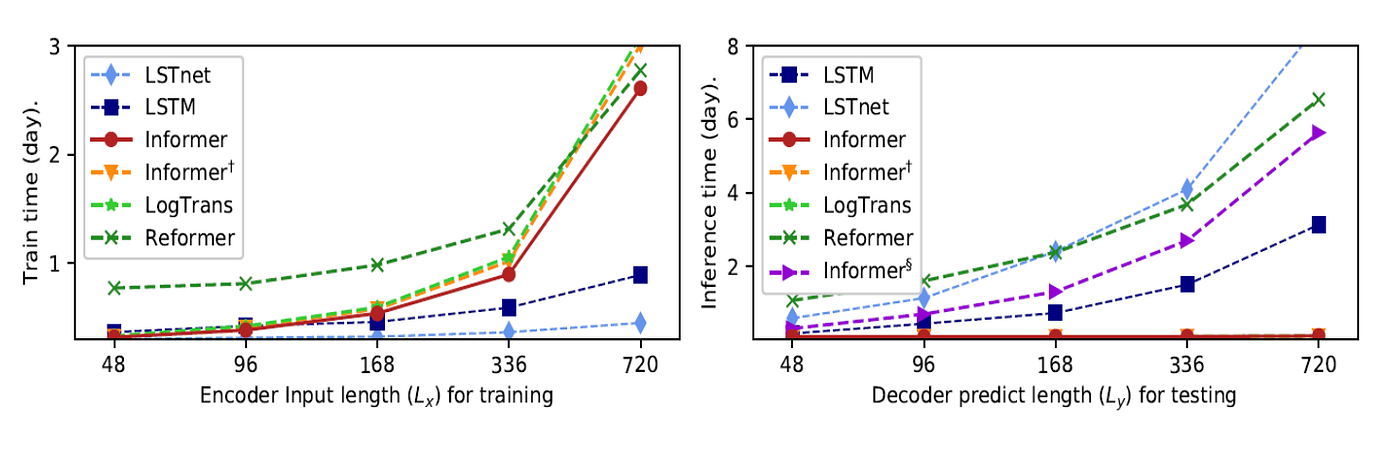
The paper reports that Informer is faster than other Transformer-based methods during training and much faster during testing because of the generative decoder.
The theoretical comparison is also important:
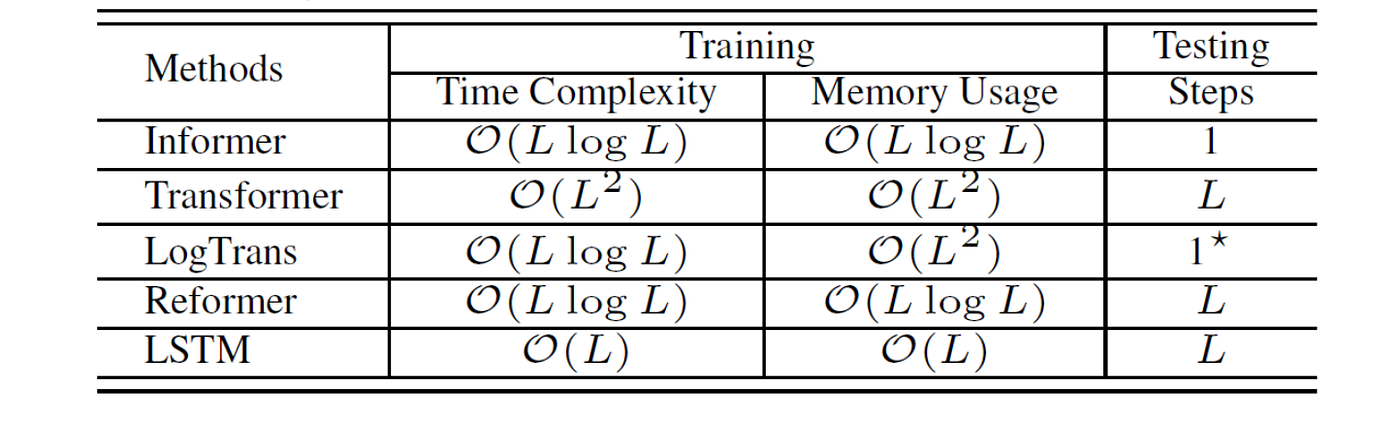
Compared with vanilla Transformer attention, Informer reduces the layer-level time and memory cost from quadratic complexity toward O(L log L). That is the difference between a method that looks good in theory and a method that can be used on longer real-world sequences.
Why Informer Matters
Informer matters because it made a concrete argument: Transformers can be useful for long sequence time-series forecasting, but only if we redesign them for the forecasting setting.
The paper is not just about adding attention to time series. It is about recognizing that LSTF has its own requirements:
- long inputs
- long outputs
- efficient inference
- robustness over long horizons
- practical memory usage
Informer addresses those requirements through architecture choices rather than treating the vanilla Transformer as a plug-and-play solution.
Limitations
Informer is an important model, but it is not the final answer to time-series forecasting.
First, ProbSparse attention depends on the assumption that useful attention is sparse. That assumption works well in the paper’s experiments, but different datasets may have different dependency structures.
Second, forecasting performance depends strongly on data quality, seasonality, covariates, and the forecast horizon. No architecture removes the need for careful data preparation and evaluation.
Third, later Transformer-based forecasting models have continued to challenge and refine the design choices made by Informer. This is normal: Informer helped open a research direction, and later work has built on, revised, or competed with its assumptions.
Finally, efficient long-range forecasting can still be misused if predictions are treated as certainty. In domains such as energy, finance, health, or infrastructure planning, model outputs should support domain experts rather than replace expert judgment.
Takeaway
Informer is a practical and influential attempt to make Transformers work for long sequence time-series forecasting.
Its three main ideas are easy to remember:
- ProbSparse attention focuses computation on the most informative attention queries.
- Self-attention distilling compresses long encoder representations across layers.
- Generative decoding predicts the full future sequence in one forward pass.
The broader lesson is that architecture should respect the problem. Long sequence forecasting is not just short sequence forecasting with a larger horizon. It needs models that can capture long-range dependencies without becoming too slow or too memory-intensive.
Informer is valuable because it takes that requirement seriously.
References
- Zhou, H., Zhang, S., Peng, J., Zhang, S., Li, J., Xiong, H., & Zhang, W. (2021). Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. Proceedings of the AAAI Conference on Artificial Intelligence, 35(12), 11106-11115.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems.
- Tay, Y., Dehghani, M., Bahri, D., & Metzler, D. (2020). Efficient Transformers: A Survey. ACM Computing Surveys.
- Informer code repository: https://github.com/zhouhaoyi/Informer2020
- ETT dataset repository: https://github.com/zhouhaoyi/ETDataset